Repetitorium
- 1 Grundlegendes zur Abschlussarbeit/Projektarbeit/Seminararbeit/Essay
- 2 Gliederung der Arbeit
- 3 Daten aus unterschiedlichen Formaten in R einlesen.
- 4 Daten für die Analyse aufbereiten (Variablen recodieren, Umgang mit Missing Values, Variabeln klassifizieren, Umbenennen von Variablennamen).
- 4.1 Verwendete Daten / Beschreibung
- 4.2 Daten anschauen (inspizieren)
- 4.3 Daten recodieren
- 4.4 -9 durch NA ersetzen
- 4.5 Fälle die weniger als 80% im Fragebogen ausgefüllt haben löschen
- 4.6 Klassifizierung von Variablen
- 4.7 Umbenennen von Variablennamen
- 4.8 Weitere nützliche Befehle
- 4.9 Der „Pipe Operator“ %>%
- 4.10 Missing Values ersetzten durch den Mittelwert der Spalte
- 4.11 Alle quantitativen Variablen auf numerisch klassifizieren
- 5 Datenstruktur prüfen (Korrelation, Dimensionsreduktion, Dimensionen zusammenfassen).
- 6 Dimensionsreduktion (Ausführlicher bei Dimensionsreduktion)
- 7 Voraussetzung für eine barrierefreie Datenanalyse.
- 8 Daten skalieren.
- 9 Grundlagen der Inferenzstatistik (Kurze Wiederholung aus dem Studium: Was ist wirklich relevant, um die Inferenz zu verstehen!
- 9.1 Test auf Normalverteilung
- 9.2 Korrelationstest
- 9.3 Lineare multiple Regressionsanalyse
- 9.4 t-Tests
- 9.5 Einfaktorielle Varianzanalyse (ANOVA)
- 9.6 Multivariate Varianzanalyse (MANOVA)
- 9.7 Post-hoc Test bei der Varianzanalyse
- 9.8 Chi-Quadrat-Unabhängigkeitstest
- 9.9 Auf was ist zu achten bei der Fragebogenerstellung (Art der Fragen, Skalierung, etc.)?
- 10 Versuchsplanung
- 11 Mögliche Darstellung von Tabellen
- 12 Wie kann ich vermeiden zu häufig gleiche Wörter zu verwenden?
© Prof. Dr. Oliver A. Gansser | oliver@gansser.de | www.gansser.de
1 Grundlegendes zur Abschlussarbeit/Projektarbeit/Seminararbeit/Essay
Folgende Unterlagen sind als Dateien zur Verfügung zu stellen:
- Arbeit als PDF (Achtung: Fragebogen kommt immer in den Anhang der Arbeit, niemals die Auswertungen, diese kommen in die Arbeit, siehe hierzu mein Leitfaden)
Alles, was wichtig ist kommt in die Arbeit und alle was nicht wichtig ist kommt nicht in die Arbeit und dann auch nicht in Anhang (Regel!).
Codebook: Hier ist die Kodierung der Fragen im Fragebogen enthalten (Genauer: Welche Variable in den Daten entspricht welcher Frage im Fragebogen, in Soscisurvey heiß dieses Codebook die Variablenliste und ist abrufbar)
Rohdatendaten als csv so codiert, dass die Daten mit dem Codebook übereinstimmen. Rohdaten sind Daten die weder bearbeitet noch bereinigt sind.
Flüchtigen Quellen (Internetseiten), als pdf.
R-Skript oder das RMarkdown der Datenanalyse.
2 Gliederung der Arbeit
Wissenschaftliche Arbeiten sind immer gleich/ähnlich gegliedert:
- Einleitung
- Theorie und Forschungsstand
- Methodik
- Ergebnisse
- Fazit/Diskussion
=> Leitfaden
3 Daten aus unterschiedlichen Formaten in R einlesen.
Wichtig: Datenfenster (rechts oben in RStudio) sollte vor dem Start der Datenanalyse immer leer sein.
Wo liegen die Daten?
=> Irgendwo in einem Ordner, oder irgendwo im WWW.
=> Einfachste Möglichkeit: Einen relativen Pfad verwenden, d.h. man gibt nur den Dateinamen mit Endung an und muss aber das Skript im gleichen Ordner haben wie die Daten.
Bsp: absoluter Pfad:
read.csv2("\user\MaxMusterman\Dokumente\Daten.csv")Bsp: relativer Pfad:
read.csv2("Daten.csv")Relativer Pfad funktioniert nur, wenn die Daten im aktuellen Arbeitsverzeichnis (WD) liegen. Kontrolle mit getwd()
Nicht zu empfehlen ist der Import über die Menüleiste in Environment, da dann mit der Maus umständlich gesucht werden muss und diese Suche nicht Skript dokumentiert werden kann.
3.1 Arbeitsverzeichnis von R Studio
getwd() #Suchen des aktuelle Arbeitsverzeichnises
setwd('C://datei/pfad') #Wechselt das aktuelle Arbeitsverzeichnis.Arbeitsverzeichnisse lassen sich aber viel einfacher wechseln, in dem R-Skripte in einem Ordner auf dem Rechner öffnet und somit das WD in diesen Ordner gesetzt wird. Das geht nur, wenn R-Studio noch nicht geöffnet ist.
Deshalb => Zum Start der Datenanalyse nicht RStudio, sondern das Skript mit RStudio öffnen.
Zur Kontrolle vom Workspace: getwd()
Wichtig noch vor dem Start: Einstellung RStudio: Tools/Global Options/Code: Hier bei Savings Default Text encoding auf UTF-8 einstellen.
Die Daten, die wir hier verwenden heißen “Daten_GFK.csv”
Achtung
Sind die Daten auch csv? Überprüfen mit: anschauen mit Text-Editor. CSV in Deutschland ist immer ; separiert
Zur Not (wenn nicht richtig abgespeichert) mit Excel öffnen und als CSV (Trennzeichen getrennt) speichern und nochmals kontrollieren mit Text-Editor.
Achtung Feldtrennzeichen: ; = deutsch (in R => csv2) und , = Rest der Welt (in R => csv)
Beim Einlesen in R lautet die Einlesefunktion für einen csv Datei:
bei ; getrennten Variablen => read.csv2()
bei , getrennten Variablen => read.csv()
3.2 Daten einlesen
Die Daten zum Repetitorium können Sie unter http://www.gansser.de/data/Daten_GFK.csv kostenlos downloaden.
- Möglichkeit: Zuerst Daten speichern, dann Daten einlesen
Wenn Sie die Daten in einen Ordner legen und dann ein Skript in R Studio anlegen, können Sie die Daten ganz einfach mit den folgenden Befehlen einlesen. Wenn Sie später mit einem R-Skript die Daten einlesen möchten, genügt das Öffnen des Skriptes und ausführen der Befehle. Dieses Vorgehen macht den Umgang mit Daten sehr einfach. Aus dem csv.2 Datenformat, wenn die Datei bereits auf dem Rechner gespeichert ist:
data<-read.csv2("Daten_GFK.csv")- Möglichkeit: Zuerst Daten einlesen, dann speichern (s.u.)
data<-read.csv2("http://www.gansser.de/data/Daten_GFK.csv")Wenn Daten aus dem Internet geladen werden, sind die Daten nicht auf dem Rechner, bevor sie nicht gespeichert werden. Insbesondere bei Apple Rechnern ist dies die bevorzugte Variable, da Apple u. u. die Daten anders abspeichern.
Tipp: Wenn Sie Ihre Arbeit unterbrechen, dann hinterlassen Sie Ihr Skript so (Speichern nicht vergessen), das sie beim Öffnen des Skriptes das Skript einfach durchlaufen lassen könne (Alles Markieren mit Str+Alt und dann Ausführen mit run) und dann an der Stelle weiterarbeiten an der Sie zuletzt gearbeitet haben. Damit werden alle Prozesse vom Einlesen bis zur Aufbereitung und Datenanalyse nochmals durchgeführt. Das hat den Vorteil, dass Sie immer nur mit einem Datensatz und mit einem funktionierenden Skript arbeiten, dass Sie dann bei der Abgabe der Arbeit zusammen mit den Daten auch fehlerfrei abgeben können. Was bei Ihnen läuft, läuft auch auf jedem anderen Rechner. Zudem kann auf diese Weise auch das Zusammenarbeiten in Projektgruppen erleichtert werden z. B. über ein gemeinsames Laufwerk (wo auch immer das liegt).
Für Projektgruppen bietet sich auch die RStudio Cloud an. Achtung: Jede Person hat nur 15 Freistunden und 15 Projekte in der Cloud.
Aus .Rdata Datenformat erfolgt das Einlesen über load und mit anderer Endung:
save(data, file="Daten_GFK.Rdata")
rm(data) #löscht den bestehenden Datensatz in der Environment
load("Daten_GFK.Rdata")# Beim Laden von Rdata Daten immer ohne ZuweisungAnmerkung: Ohne eine Zuweisung mit data<- werden die Daten nur eingelesen, aber nicht in die Arbeitsumgebung (Environment) von R geladen.
<- ist ein Zuweisungsbefehl, der das was rechts davon steht, dem Objekt links davon zuweist. In unserem Fall die eingelesenen Daten dem data.frame data. Somit zeugt und RStudio in der Environment rechts den Datensatz data an.
3.3 Daten speichern
Als csv Daten:
write.csv2(data, file = "filename.csv") # Achtung auch hier wieder auf deutsches Format achtenAls RData:
save(data, file = "filename.Rdata)In der Regel erfordert das Arbeit mit Rohdaten und einem R-Skript kein Speichern von bearbeiten Daten, da die Bearbeitung über das Skript läuft. D. h. alle Änderungen erfolgen mit Ausführung des Skriptes, es lässt sich somit ein Datensalat (Im Sinne von veränderten Daten oder Daten die jeden Tag neu abgespeichert werden müssen) vermeiden.
4 Daten für die Analyse aufbereiten (Variablen recodieren, Umgang mit Missing Values, Variabeln klassifizieren, Umbenennen von Variablennamen).
# Laden von Mosaic (ggf. vorher installieren mit install.packages())
library(mosaic)4.1 Verwendete Daten / Beschreibung
In der nachfolgenden Analyse wird ein Datensatz verwenden bei dem die Berufliche Belastung und die Gesundheit als multiattributives Konstrukt gemessen wurde. Zusätzlich wurde die Berufliche Belastung als Auswahlentscheidung (ja/nein) gemessen. Außerdem wurde das Geschlecht und der akademische Abschluss erfasst. Nachfolgend ist die Codierung der Konstrukte (oder in diesem Fall sogar das Codebook) aufgelistet:
| Berufliche Belastung (Maslach MBI) | Items |
|---|---|
| V3_1 | Ich fühle mich von meiner Arbeit emotional ausgelaugt. |
| V3_2 | Ich fühle mich am Ende eines Arbeitstages geschafft. |
| V3_3 | Ich fühle mich erschöpft, wenn ich morgens aufstehe und wieder einen Arbeitstag vor mir habe. |
| V3_4 | Immer mit Menschen zu arbeiten, bedeutet eine große Anspannung für mich. |
| V3_5 | Ich fühle mich ausgebrannt von meiner Arbeit. |
| V3_6 | Ich fühle mich frustriert in meinem Beruf. |
| V3_7 | Ich fühle, dass ich in meinem Beruf zu hart arbeite. |
| V3_8 | Es bedeutet für mich zu viel Stress, direkt mit Menschen zu arbeiten. |
| V3_9 | Ich habe das Gefühl, als ob ich am Ende wäre. |
| Berufliche Belastung | Item |
|---|---|
| V8 | Wenn Sie eine Entscheidung treffen müssten, wie würden Sie antworten? (ja = 1, nein = 2) |
| Gesundheit | V9 = Gesundheit am AP, V10 = allgemeine Gesundheit |
|---|---|
| V9_1 | Waren Sie in den letzten 12 Monaten aufgrund ihrer Arbeitsbelastung oft krankgeschrieben? |
| V9_2 | Haben Sie den Wunsch nach einer Auszeit? |
| V9_3 | Hatten Sie schon einmal darüber nachgedacht, alles hinzuschmeißen? |
| V9_4 | Gibt es in Ihrem Unternehmen psychisch beanspruchte Mitarbeiter mit auffälligem Arbeitsverhalten? |
| V10_1 | Konzentrationsstörungen |
| V10_2 | Schlafstörungen |
| V10_3 | Antriebslosigkeit |
| V10_4 | Müdigkeitserscheinungen |
| V10_5 | Überlastungserscheinungen |
| V10_6 | Angespanntheitserscheinungen |
| Soziodemographische Daten | |
|---|---|
| V11_1 | Was für ein Geschlecht haben Sie? (männlich = 1, weiblich = 2) |
| V11_3 | Haben Sie einen akademischen Abschluss? |
4.2 Daten anschauen (inspizieren)
mosaic::inspect(data[1:21]) # das Paket mosaic wird oft von anderen Paketen überdeckt, deswegen sicherheitshalber mosaic nochmals speziell für diesen Befehl laden mit mosaic::##
## quantitative variables:
## name class min Q1 median Q3 max mean sd n missing
## 1 V3_1 integer 1 2.00 3.0 5.00 6 3.335821 1.440259 134 0
## 2 V3_2 integer 1 2.00 3.0 4.00 6 2.985075 1.359926 134 0
## 3 V3_3 integer -9 2.00 4.0 5.00 6 3.701493 1.923460 134 0
## 4 V3_4 integer -9 3.25 5.0 5.00 6 4.343284 1.856120 134 0
## 5 V3_5 integer -9 3.00 5.0 5.00 6 4.208955 1.911873 134 0
## 6 V3_6 integer -9 3.00 4.0 6.00 6 3.895522 2.528837 134 0
## 7 V3_7 integer -9 2.00 3.0 5.00 6 3.313433 2.132519 134 0
## 8 V3_8 integer -9 4.00 5.0 6.00 6 4.589552 2.177163 134 0
## 9 V3_9 integer 1 4.00 5.0 6.00 6 4.731343 1.532427 134 0
## 10 V8 integer -9 1.00 1.0 2.00 2 1.022388 1.824917 134 0
## 11 V9_1 integer 1 4.25 6.0 6.00 6 4.932836 1.467430 134 0
## 12 V9_2 integer 1 2.00 3.0 5.00 6 3.373134 1.817507 134 0
## 13 V9_3 integer 1 1.00 3.0 5.00 6 3.388060 1.969353 134 0
## 14 V9_4 integer 1 1.25 2.5 4.00 6 2.880597 1.617781 134 0
## 15 V10_1 integer 1 2.00 4.0 5.75 6 3.992537 1.692515 134 0
## 16 V10_2 integer 1 2.00 5.0 5.75 6 4.059701 1.711356 134 0
## 17 V10_3 integer 1 2.00 4.0 5.00 6 3.858209 1.730544 134 0
## 18 V10_4 integer -9 2.00 3.0 5.00 6 3.089552 1.997979 134 0
## 19 V10_5 integer 1 2.00 3.0 5.00 6 3.619403 1.684939 134 0
## 20 V10_6 integer 1 2.00 3.0 5.00 6 3.447761 1.706102 134 0
## 21 V11_1 integer -9 1.00 1.0 2.00 2 1.052239 2.045781 134 04.3 Daten recodieren
Daten, falls nötig recodieren. Die Notwendigkeit erkennen Sie entweder im Vorfeld beim Anlegen des Fragebogens (also in diesem Fall im Fragebogen nachschauen) oder spätestens bei der PCA wenn eine Ladung negativ ist (s.u.):
Recodiert werden müssen Variablen dann, wenn Sie von ihrer inhaltlichen Aussage in eine Richtung gehen, aber in der Formulierung in eine andere Richtung gehen.
Z. B:
Frage 1: Ich finde BMW geil! (Skaliert von 1 = stimme überhaupt nicht zu bis 6 = stimme voll und ganz zu) Frage 2: Ich finde BMW bescheuert! (Skaliert von 1 = stimme überhaupt nicht zu bis 6 = stimme voll und ganz zu)
Wenn in diesem Fall die Einstellung zum BMW über den Mittelwert (mean) gemessen werden soll, würde dies zu einer Fehlinterpretation führen.
In diesem Fall muss eine der Variablen recodiert werden:
# 5 Personen werden befragt
Frage1<-c(6,5,6,6,5)
Frage2<-c(1,2,1,3,1)
Beispieldaten<-cbind(Frage1, Frage2)
Beispieldaten<-as.data.frame(Beispieldaten)
# Frage 2 soll recodiert werden
# Es wird immer vom Maximalwert +1 addiert (6+1=7).
# Und von dieser Zahl werden die zu recodierenden Daten subtrahiert
# 7-1=6, 7-2=5 ext.
Beispieldaten$Frage2<-7-Beispieldaten$Frage2
Beispieldaten## Frage1 Frage2
## 1 6 6
## 2 5 5
## 3 6 6
## 4 6 4
## 5 5 64.4 -9 durch NA ersetzen
Bei vielen Online-Befragungsplattformen werden fehlende Werte (Missing Values) mit -9 abgespeichert. Das erkennen Sie mit inspect(), wenn beim min von favstats() die -9 steht. Würde man nun weiter die Daten analysieren, ohne die -9 richtig zu behandeln, würde -9 als Werte gerechnet werden und somit die Analyse verfälschen (Die Analyse wäre Makulatur).
Deshalb ersetzten wird -9 mit NA (not available) um dieses Feld als Missing Value zu kennzeichnen.
[] wird in R immer dann benötigt, wenn aus einem Datensatz (das Objekt vor der []) bestimmte Zellen angesprochen werden sollen. Anschließend wird mit <- die Zuweisung durchgeführt für diese Zellen.
NA ist in R immer ein leeres Feld.
data[data == -9] <- NA
inspect(data)##
## categorical variables:
## name class levels n missing
## 1 V11_3 character 4 132 2
## distribution
## 1 Uni (37.9%) ...
##
## quantitative variables:
## name class min Q1 median Q3 max mean sd n missing
## 1 V3_1 integer 1 2.00 3.0 5.00 6 3.335821 1.4402591 134 0
## 2 V3_2 integer 1 2.00 3.0 4.00 6 2.985075 1.3599263 134 0
## 3 V3_3 integer 1 2.00 4.0 5.00 6 3.796992 1.5799856 133 1
## 4 V3_4 integer 1 4.00 5.0 5.00 6 4.443609 1.4533844 133 1
## 5 V3_5 integer 1 3.00 5.0 5.00 6 4.308271 1.5333685 133 1
## 6 V3_6 integer 1 3.00 5.0 6.00 6 4.190840 1.6177596 131 3
## 7 V3_7 integer 1 2.00 3.0 5.00 6 3.500000 1.5057143 132 2
## 8 V3_8 integer 1 4.00 5.0 6.00 6 4.795455 1.3964985 132 2
## 9 V3_9 integer 1 4.00 5.0 6.00 6 4.731343 1.5324273 134 0
## 10 V8 integer 1 1.00 1.0 2.00 2 1.330769 0.4723102 130 4
## 11 V9_1 integer 1 4.25 6.0 6.00 6 4.932836 1.4674297 134 0
## 12 V9_2 integer 1 2.00 3.0 5.00 6 3.373134 1.8175073 134 0
## 13 V9_3 integer 1 1.00 3.0 5.00 6 3.388060 1.9693533 134 0
## 14 V9_4 integer 1 1.25 2.5 4.00 6 2.880597 1.6177808 134 0
## 15 V10_1 integer 1 2.00 4.0 5.75 6 3.992537 1.6925146 134 0
## 16 V10_2 integer 1 2.00 5.0 5.75 6 4.059701 1.7113561 134 0
## 17 V10_3 integer 1 2.00 4.0 5.00 6 3.858209 1.7305438 134 0
## 18 V10_4 integer 1 2.00 3.0 5.00 6 3.180451 1.7048709 133 1
## 19 V10_5 integer 1 2.00 3.0 5.00 6 3.619403 1.6849389 134 0
## 20 V10_6 integer 1 2.00 3.0 5.00 6 3.447761 1.7061021 134 0
## 21 V11_1 integer 1 1.00 1.0 2.00 2 1.441860 0.4985444 129 54.5 Fälle die weniger als 80% im Fragebogen ausgefüllt haben löschen
# data<-data[-which(rowMeans(is.na(data)) > 0.2), ]
# Achtung: Funktioniert nur, wenn auch solche Fälle im Datensatz sind!!!
# Alternativ kann auch einen Variablenauswahl vorgenommen werden mit is.na(data[])4.6 Klassifizierung von Variablen
4.6.1 Klassentypen
Bei manchen Analyseverfahren ist ein bestimmter Variablentyp notwendig. Eine Umklassifizierung erfolgt mitas.neueKlasse
data$Variable<- as.logical(data$Variable)
data$Variable<- as.numeric(data$Variable)
data$Variable<- as.character(data$Variable)
data$Variable<- as.factor(data$Variable)- B. Ist es sinnvoll, den Bildungsabschluss als Faktorvariable zu klassifizieren. Hier werden intern in R Zahlenwerte (levels) gespeichert, die auch eine bestimmte Reihenfolge haben.
levels(data$V11_3) # nicht sichbar## NULLstr(data$V11_3) # Es gibt 134 Wörter in der Variable## chr [1:134] "Uni" "Keinen akademischen Abschluss" "Fachhochschule" "Uni" ...data$V11_3<- as.factor(data$V11_3) # Umklassifizieren als Faktor
levels(data$V11_3) # Anzeige der levels nur mit Faktorvariable möglich## [1] "Fachhochschule" "Hochschule"
## [3] "Keinen akademischen Abschluss" "Uni"str(data$V11_3) # Levels sind dann nummeriert## Factor w/ 4 levels "Fachhochschule",..: 4 3 1 4 3 4 4 2 4 2 ...Falls Variablen nicht als Charakter eingelesen werden können, dann existiert das Problem, dass Variablen mit -9 für den Wert -9 einen Faktor bilden. Dieser kann eliminiert werden, in dem die Variable zuerst als Charakter klassifiziert wird, und dann erst -9 mit NA ersetzt wird. Anschließen kann diese Variable als Faktor klassifiziert werden.
4.6.2 Inhalt der Daten ändern/umbenennen
Wir sehen in der Rohdatenmatrix, dass V8 und V11_1 noch numerisch sind, aber eigentlich kategorial sein müssen.
inspect(data$V8)## # A tibble: 1 × 10
## class min Q1 median Q3 max mean sd n missing
## * <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
## 1 integer 1 1 1 2 2 1.33 0.472 130 4inspect(data$V11_1)## # A tibble: 1 × 10
## class min Q1 median Q3 max mean sd n missing
## * <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
## 1 integer 1 1 1 2 2 1.44 0.499 129 5# Diesen Zahlen muss ein Faktor zugewiesen werden
# numerisch in factor wandeln
data$V8<-as.factor(data$V8)
# Levels anzeigen
levels(data$V8)## [1] "1" "2"# Wörter zuweisen
levels(data$V8)<-c("ja", "nein")
levels(data$V8) # Im Datensatz wurde bei V8 1 mit ja und 2 mit nein ersetzt.## [1] "ja" "nein"Hier nochmal mit Geschlecht (V11_1)
data$V11_1<-as.factor(data$V11_1)
levels(data$V11_1)## [1] "1" "2"levels(data$V11_1)<-c("männlich", "weiblich")
levels(data$V11_1)## [1] "männlich" "weiblich"4.6.3 Levels tauschen
# setzt weiblich auf das erste level
data$V11_1 <- relevel(data$V11_1, "weiblich")
levels(data$V11_1)## [1] "weiblich" "männlich"Mehr dazu hier
4.6.4 Ersetzen von Inhalt B bei Variable XYZ mit Inhalt b
=> Vorher Variable duplizieren, da die Daten ja überschrieben werden.
data$XYZ<-data$ABC # aus Variable ABC wird Variabel XYZ
Das Ersetzen geht dann mit
data$XYZ[data$XYP == "B"] <- "b"
4.7 Umbenennen von Variablennamen
Es bietet sich an, bestimmt Variablen wie z. B. Geschlecht auch so zu benennen
Hilfreich ist an diese Stelle, wenn die Variablennummer der Variable bekannt ist. Einen Ausgabe der Variablennummerierung bekommt man mit t(colnames(data)). Wichtig: Variablennamen sollten nicht durch Leerzeichen getrennt sein. Stattdessen verwenden Sie ..
t(colnames(data))## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
## [1,] "V3_1" "V3_2" "V3_3" "V3_4" "V3_5" "V3_6" "V3_7" "V3_8" "V3_9" "V8"
## [,11] [,12] [,13] [,14] [,15] [,16] [,17] [,18] [,19]
## [1,] "V9_1" "V9_2" "V9_3" "V9_4" "V10_1" "V10_2" "V10_3" "V10_4" "V10_5"
## [,20] [,21] [,22]
## [1,] "V10_6" "V11_1" "V11_3"names(data)[21] <- c("Geschlecht") # Name der Variable Nr. 21 wird mit "Geschlecht" überschrieben.
names(data)[22] <- c("Bildungsabschluss")
names(data)[10] <- c("Berufliche.Belastung")
t(colnames(data))## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
## [1,] "V3_1" "V3_2" "V3_3" "V3_4" "V3_5" "V3_6" "V3_7" "V3_8" "V3_9"
## [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17]
## [1,] "Berufliche.Belastung" "V9_1" "V9_2" "V9_3" "V9_4" "V10_1" "V10_2" "V10_3"
## [,18] [,19] [,20] [,21] [,22]
## [1,] "V10_4" "V10_5" "V10_6" "Geschlecht" "Bildungsabschluss"Alternativ geht auch:
names(data)<-c("Geschlecht","Bildungsabschluss","Berufliche.Belastung","usw.") … in der Reihenfolge der Variablen.
4.8 Weitere nützliche Befehle
head(data) # gibt den Kopf (ersten 6 Zeilen) eines Datensatzes aus.
ls(data) # listet alle geladenen Objekte (hier die Variablen) auf
rm(data) #löscht geladene einzelne Objekte
data[1:10,c(10,21)] #zeigt die Zeile 1 bis 10 und Variable 10 und 21
data[1:10,] # zeigt die Zeile 1 bis 10 und alle Variablen
data[1,] # zieht eine Zeile aus den Daten, hier die Zeile 1
data[,1] # Zieht eine Spalte aus den Daten, hier die Spalte 1
data[1,10] # Zieht den Wert von Zeile 1 und Spalte 10 aus den Daten
nrow(data) # Anzahl Zeilen in der Matrix
ncol(data) # Anzahl Spalten in der Matrix
dim(data) # Anzahl Zeilen und Spalten in der Matrix
# Frage: Welche Zahle steht in Zeile 111 und Spalte 5?
data[111,5]
# Frage: Welche Zahlen stehen in Zeile 111 und 122 und Spalte 5?
data[c(111,122),5] # c = combine
# Frage: Welche Zahlen stehen in Zeile 111 und 122 und Spalte 10 und 21?
data[c(111,122),c(10,21)]
# Frage: Wie kann ich die letzte Matrix als eigenen Datensatz als `ds` speichern?
ds<-data[c(111,122),c(10,21)]
ds4.9 Der „Pipe Operator“ %>%
Short-cut: Str/Shift/m
kann über das Paket library(dplyr) geladen werden, wird aber auch aus anderen Paketen, wie im nächsten Chunk, mit geladen. Wenn eine Fehlermeldung kommt, dann einfach dplyr nachladen.
Anmerkung: Das gilt im Übrigen für alle Fehlermeldungen. In der Regel lassen sich in R Fehler beheben, in dem man die Fehlermeldung durchliest und dann den Empfehlungen folgt. Notfalls den Fehler in eine Suchmaschine eingeben oder kopieren.
Eine passendere deutsche Übersetzung für diesen Operator ist „Rohr“ (engl. pipe) und funktioniert folgendermaßen:
- Nimm einen Datensatz (oder ein Daten-Objekt)
- Gib ihn mittels Rohrpost %>% an die nächste Zeile weiter
- Verkette so viele Funktionen, wie Du möchtest
Vorteil: Besser lesbarer Code und man kann geschachtelten Klammerausdrücke auflösen, und man muss Zwischenergebnisse nicht in Objekten speichern. Man kann auch schön Schritt für Schritt die ToDos bis zum %>% ausführen. Es lässt sich Schritt für Schritt nachverfolgen, was mit den Daten passiert.
Beispiel:
library(dplyr) # ggf vorher installieren mit install.packages ("dplyr")
mtcars%>%
select(mpg,cyl) %>%
filter(cyl>6) %>%
filter(mpg<15) ## mpg cyl
## Duster 360 14.3 8
## Cadillac Fleetwood 10.4 8
## Lincoln Continental 10.4 8
## Chrysler Imperial 14.7 8
## Camaro Z28 13.3 8Probieren Sie selbst aus was passiert, wenn nur bis vor die ersten Pipe ausgeführt wird, dann die zweite, dritte und dann den ganzen Code.
Hinweise: Wenn im Code die Pipe genutzt wird und Sie den ganzen Code ausführen wollen, muss der Curser nur irgendwo im Code stehe. Sie müssen nicht dann ganzen Code markieren. Wenn jedoch markiert wird, wird auch nur der markierte Teil ausgeführt.
4.10 Missing Values ersetzten durch den Mittelwert der Spalte
Manche Verfahren (z. B. Korrelationsanalyse) akzeptieren keine NAs. D. h. ich muss was mit den NAs machen. Eine Möglichkeit ist, alle Fälle mit NAs zu löschen. Eine zweite Möglichkeit ist das Ersetzen durch andere Werte (z. B. der Mittelwert der Spalte). na_mean wird für alle metrischen Variablen ausgeführt.
Achtung: Faktoren wie Geschlecht etc. müssen vorher als Faktoren klassifiziert werden, sonst gibt es Mittelwerte beim Geschlecht.
Diese Vorgehensweise hat den Vorteil, dass sich die Mittelwerte der Spalten nicht verändern. D. h. der Mittelwert vor dem Ersetzen = Mittelwert nach dem Ersetzen. Dies sollten man allerdings nur durchführen, wenn nicht zu viele fehlende Werte pro Variable im Datensatz sind (max. ca. 20 Prozent je Variable).
library(imputeTS) #(ggf. vorher installieren mit install.packages())
data<-data%>%
na_mean() # nur die metrischen Variablen
inspect(data)##
## categorical variables:
## name class levels n missing
## 1 Berufliche.Belastung factor 2 130 4
## 2 Geschlecht factor 2 129 5
## 3 Bildungsabschluss factor 4 132 2
## distribution
## 1 ja (66.9%), nein (33.1%)
## 2 männlich (55.8%), weiblich (44.2%)
## 3 Uni (37.9%) ...
##
## quantitative variables:
## name class min Q1 median Q3 max mean sd n missing
## 1 V3_1 integer 1 2.00 3.00000 5.00 6 3.335821 1.440259 134 0
## 2 V3_2 integer 1 2.00 3.00000 4.00 6 2.985075 1.359926 134 0
## 3 V3_3 numeric 1 2.00 4.00000 5.00 6 3.796992 1.574035 134 0
## 4 V3_4 numeric 1 4.00 5.00000 5.00 6 4.443609 1.447910 134 0
## 5 V3_5 numeric 1 3.00 5.00000 5.00 6 4.308271 1.527593 134 0
## 6 V3_6 numeric 1 3.00 4.19084 6.00 6 4.190840 1.599410 134 0
## 7 V3_7 numeric 1 2.00 3.00000 5.00 6 3.500000 1.494350 134 0
## 8 V3_8 numeric 1 4.00 5.00000 6.00 6 4.795455 1.385959 134 0
## 9 V3_9 integer 1 4.00 5.00000 6.00 6 4.731343 1.532427 134 0
## 10 V9_1 integer 1 4.25 6.00000 6.00 6 4.932836 1.467430 134 0
## 11 V9_2 integer 1 2.00 3.00000 5.00 6 3.373134 1.817507 134 0
## 12 V9_3 integer 1 1.00 3.00000 5.00 6 3.388060 1.969353 134 0
## 13 V9_4 integer 1 1.25 2.50000 4.00 6 2.880597 1.617781 134 0
## 14 V10_1 integer 1 2.00 4.00000 5.75 6 3.992537 1.692515 134 0
## 15 V10_2 integer 1 2.00 5.00000 5.75 6 4.059701 1.711356 134 0
## 16 V10_3 integer 1 2.00 4.00000 5.00 6 3.858209 1.730544 134 0
## 17 V10_4 numeric 1 2.00 3.00000 5.00 6 3.180451 1.698449 134 0
## 18 V10_5 integer 1 2.00 3.00000 5.00 6 3.619403 1.684939 134 0
## 19 V10_6 integer 1 2.00 3.00000 5.00 6 3.447761 1.706102 134 04.11 Alle quantitativen Variablen auf numerisch klassifizieren
Da durch na.mean() die Variablen bei denen NAs ersetzt wurden nun numerisch sind, weil nicht mehr nur ganzzahlige Werte, können nun alle anderen Interger Variablen (ganzzahlige) zwecks der Einheitlichkeit ebenfalls als numerische Variablen klassifiziert werden. Wir verwenden den Befehl mutate_if
data<-data%>%
mutate_if(is.integer, as.numeric)5 Datenstruktur prüfen (Korrelation, Dimensionsreduktion, Dimensionen zusammenfassen).
Bevor Signifikanztest oder Zusammenhänge oder Abhängigkeiten bezüglich der aufgestellten Forschungshypothesen durchgeführt werden können, sollten die Daten hinsichtlich vorhandener Konstrukte überprüft werden. D. h. sind Konstrukte und deren Unterschiede/Zusammenhänge/Abhängigkeiten methodisch über die Datenerhebung erfasst worden, weil aus der Theorie zuvor so abgeleitet, dann müssen diese Konstrukte auch in den Daten wieder zu finden sein.
Beispiel: Sie wollen die unterschiedliche Reaktanz zwischen Männern und Frauen untersuchen, dann gibt es dazu Theorie, es wurde auch eine Hypothese abgeleitet und für die Datenerhebung wurden 5 Items zur Messung von Reaktanz und das Geschlecht erfasst (Operationalisierung). In Daten sind dann eine Variable für Geschlecht und 5 Variablen für die Reaktanz. Diese 5 Variablen sind nun bezüglich ihrer Struktur für das Konstrukt Reaktanz zu überprüfen und es ist eine neue Variabel zu bilden mit dem Namen Reaktanz.
5.1 Kontrolle der Variablennummern
Oftmals ist es nützlich zu wissen, welche Variable in welcher Spalte im Datensatz steht. Bsp. will man für eine Analyse die Variablen 1 bis 9 analysieren.
t(colnames(data))## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
## [1,] "V3_1" "V3_2" "V3_3" "V3_4" "V3_5" "V3_6" "V3_7" "V3_8" "V3_9"
## [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17]
## [1,] "Berufliche.Belastung" "V9_1" "V9_2" "V9_3" "V9_4" "V10_1" "V10_2" "V10_3"
## [,18] [,19] [,20] [,21] [,22]
## [1,] "V10_4" "V10_5" "V10_6" "Geschlecht" "Bildungsabschluss"Variable 1 bis 9: Berufliche Belastung Variable 11 bis 20 Gesundheit
Es existiert keine Variable die Gesundheit oder Berufliche Belastung heißt, stattdessen gibt es viele Items dazu.
5.2 Korrelation
Um ein Konstrukt hinsichtlich der Messbarkeit über seine Items als erstes zu inspizieren, empfiehlt sich bei metrischen Daten die Korrelationsanalyse. Hierbei ist darauf zu achten, dass die Daten keine Nas mehr enthalten (s.o.).
Der Befehl für die Korrelation lautet cor() und um die Auswahl einzelnen Variablen zu korrelieren verwendet man die []
cor(data[1:9])## V3_1 V3_2 V3_3 V3_4 V3_5 V3_6 V3_7
## V3_1 1.0000000 0.6935573 0.5881608 0.3927289 0.6316085 0.5005854 0.5292586
## V3_2 0.6935573 1.0000000 0.5964152 0.3237101 0.4716255 0.4090624 0.4717270
## V3_3 0.5881608 0.5964152 1.0000000 0.4049673 0.5958989 0.5978151 0.3637820
## V3_4 0.3927289 0.3237101 0.4049673 1.0000000 0.6146430 0.4983124 0.4175743
## V3_5 0.6316085 0.4716255 0.5958989 0.6146430 1.0000000 0.7597488 0.5682926
## V3_6 0.5005854 0.4090624 0.5978151 0.4983124 0.7597488 1.0000000 0.5083527
## V3_7 0.5292586 0.4717270 0.3637820 0.4175743 0.5682926 0.5083527 1.0000000
## V3_8 0.3601449 0.2513178 0.3689557 0.7673639 0.6070410 0.5768449 0.4371243
## V3_9 0.5147096 0.4057528 0.5626059 0.5334195 0.8163757 0.7567309 0.5351847
## V3_8 V3_9
## V3_1 0.3601449 0.5147096
## V3_2 0.2513178 0.4057528
## V3_3 0.3689557 0.5626059
## V3_4 0.7673639 0.5334195
## V3_5 0.6070410 0.8163757
## V3_6 0.5768449 0.7567309
## V3_7 0.4371243 0.5351847
## V3_8 1.0000000 0.6140501
## V3_9 0.6140501 1.0000000Besser analysieren lassen sich Korrelationen über einen corplot(). Geht nur über das Paket corrrplot. hclust ordnet die Items in der Reihenfolge der hierarchischen Clusteranalyse, um Muster (hier Quadrate) zu erkennen. Quadrate mit dunkelblauen Bubbles deuten auf Korrelationen der jweiligen Items hin.
library(corrplot) #ggf. ## corrplot 0.92 loadedcorrplot(cor(data[1:9]), order="hclust") 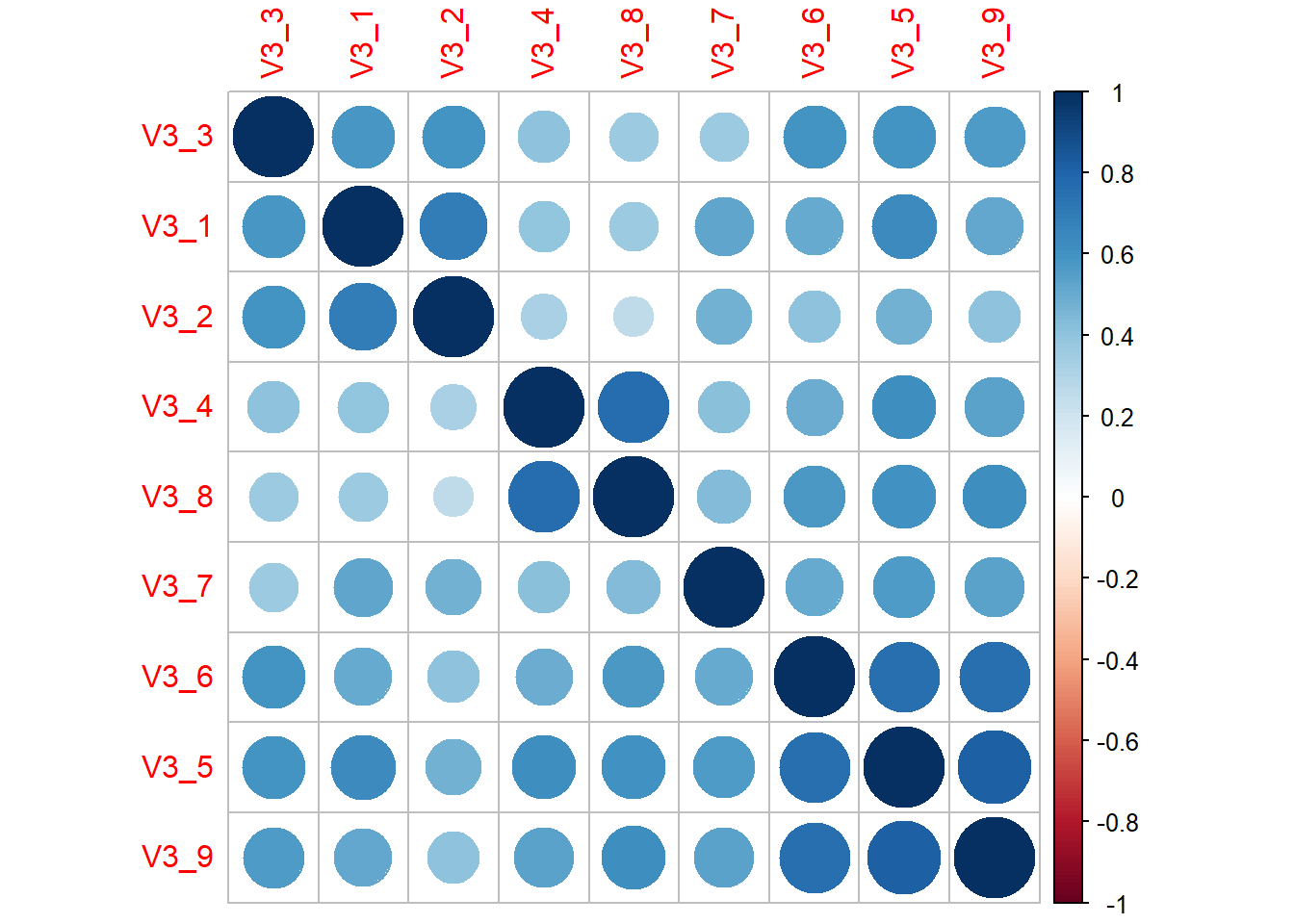
Mit dem Paket PerformanceAnalytics lassen sich Korrelationen visuell und bezüglich der Signifikanz anschaulich darstellen.
library(PerformanceAnalytics)#(ggf. vorher installieren mit install.packages())Besser ist ein chart.Correlation Plot. Der zeigt nicht nur die Korrelationen, sondern auch die Verteilung, den xyPplot und die Signifikanz der Korrelationen.
data[,1:9]%>% # Alternativ anstatt 1:9 geht auch c(1,2,3,4,...9)
chart.Correlation()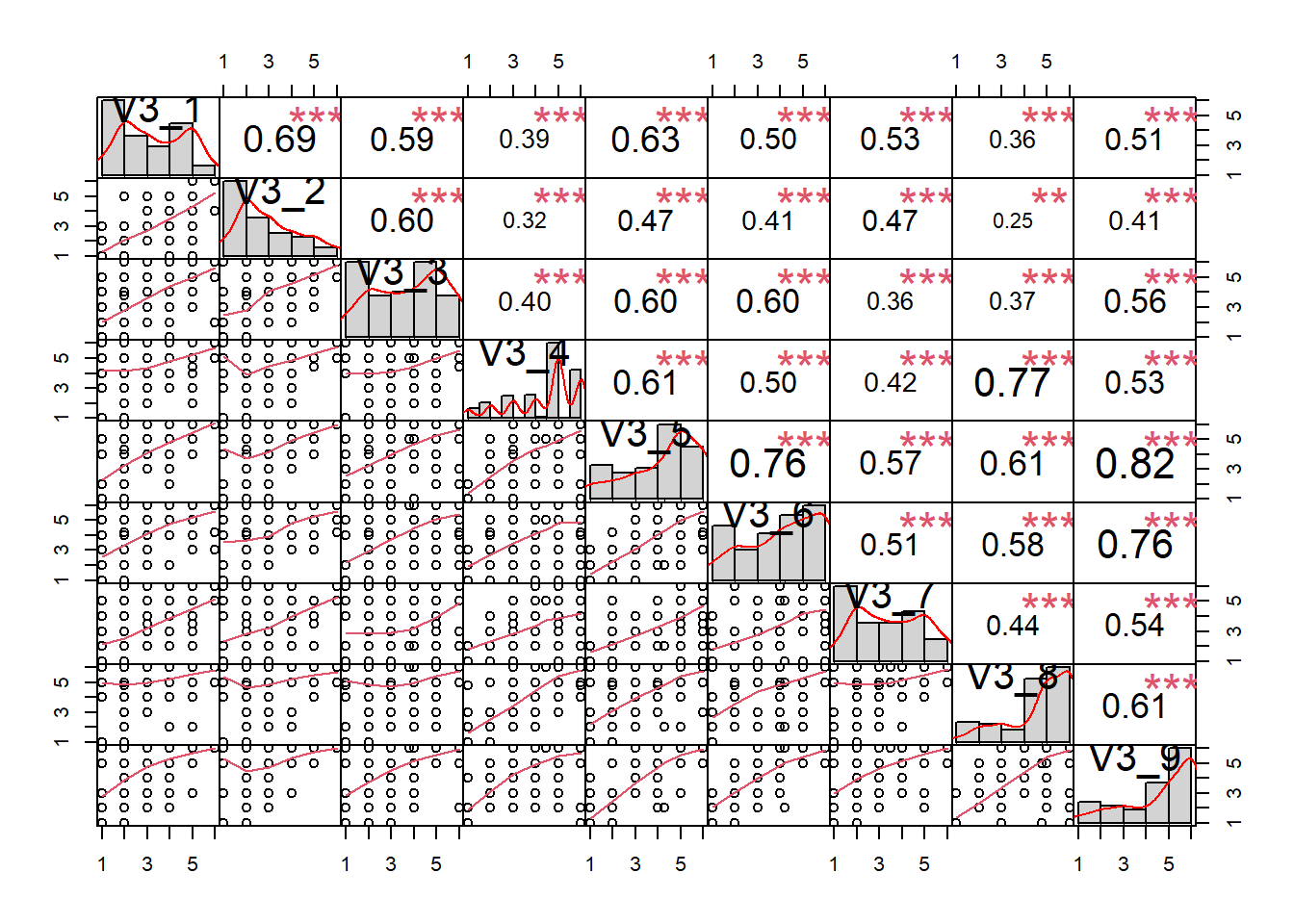
# chart.Correlation(data[,1:9]) Alternativ ohne PfeifeAllgemein gilt: Ab einer Korrelation von 0,5 spricht man von Korrelation im Sinne von “es gibt einen Zusammenhang”.
6 Dimensionsreduktion (Ausführlicher bei Dimensionsreduktion)
Pakete laden
library(nFactors) #(ggf. vorher installieren mit install.packages())
library(ltm) # für Alpha #(ggf. vorher installieren mit install.packages())
library(psych) #(ggf. vorher installieren mit install.packages())6.1 Screeplot
Der Screeplot mit dem Befehl VSS.scree() zeigt die Anzahl an Komponenten (Items die Konstrukte erklären) die aus der angegebenen Anzahl Variablen (Items) extrahiert werden können. Das Kriterium lautet: Nimm die Anzahl Komponenten, die einen Eigenwert > 1 aufweisen.
VSS.scree(data[1:9])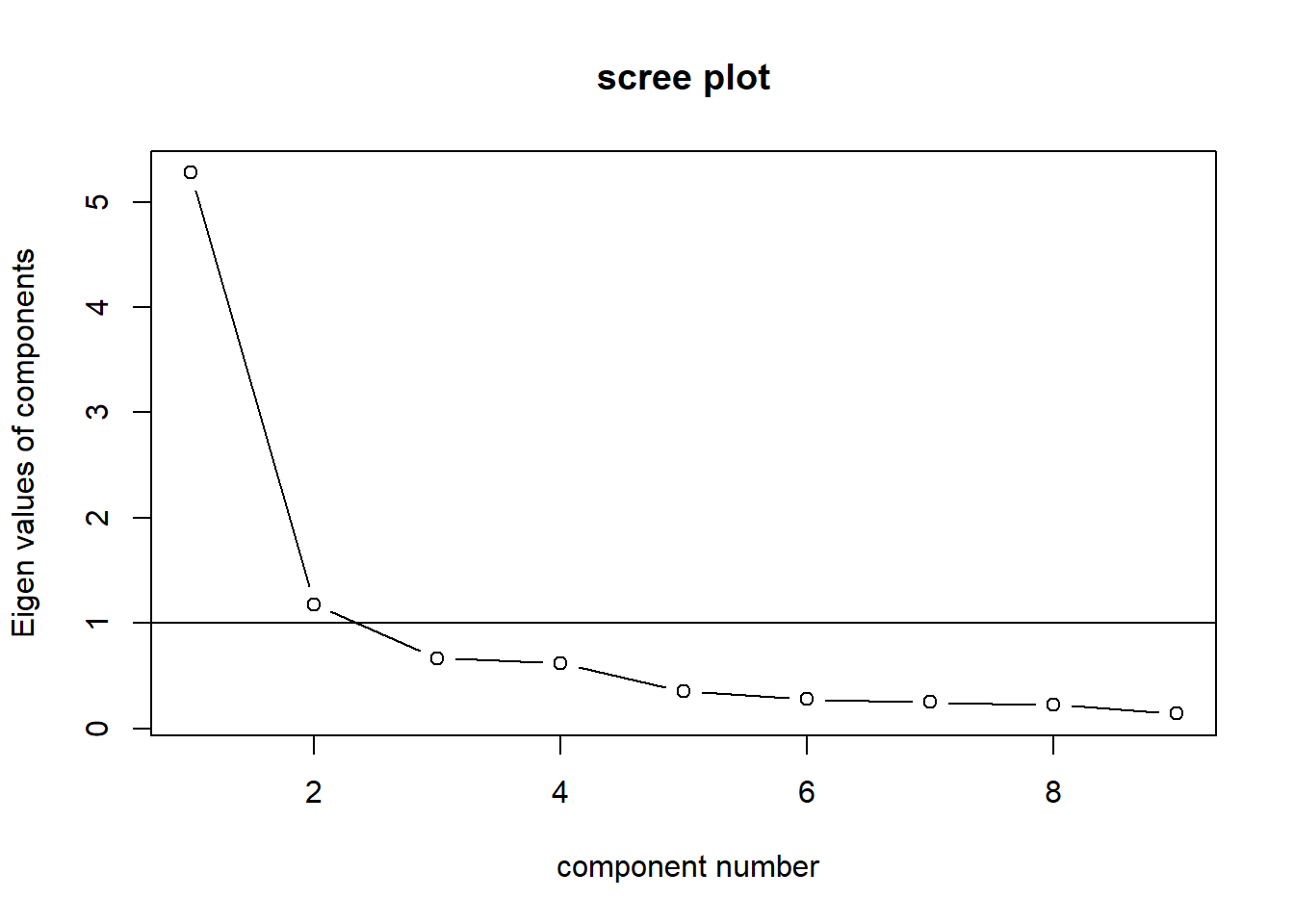 Ergebnis: Zwei Komponenten haben hier einen Eigenwert > 1. Der Korrelationsplot zeigt aber 3 Komponenten. Für die PCA verwenden wir das Ergebnis des Screeplots.
Ergebnis: Zwei Komponenten haben hier einen Eigenwert > 1. Der Korrelationsplot zeigt aber 3 Komponenten. Für die PCA verwenden wir das Ergebnis des Screeplots.
6.2 PCA (Principal component analysis = Hauptkomponentenanalyse)
Mit der PCA können die Komponenten sichtbar gemacht werden. Da nur zwei Komponenten > 1 sind, sind auch nur zwei Komponenten zu analysieren bzw. sichtbar zu machen. Es wird sodann die Anzahl 2 in den principal Befehl eingetragen.
pca<-principal(data[1:9], 2) # hier nicht vergessen die Anzahl Komponenten einzutragen
print(pca, cut=0.4, sort=TRUE)## Principal Components Analysis
## Call: principal(r = data[1:9], nfactors = 2)
## Standardized loadings (pattern matrix) based upon correlation matrix
## item RC1 RC2 h2 u2 com
## V3_8 8 0.90 0.81 0.19 1.0
## V3_4 4 0.83 0.71 0.29 1.1
## V3_9 9 0.74 0.45 0.75 0.25 1.7
## V3_5 5 0.72 0.53 0.81 0.19 1.8
## V3_6 6 0.69 0.47 0.70 0.30 1.8
## V3_2 2 0.88 0.78 0.22 1.0
## V3_1 1 0.83 0.76 0.24 1.2
## V3_3 3 0.73 0.64 0.36 1.4
## V3_7 7 0.46 0.53 0.49 0.51 2.0
##
## RC1 RC2
## SS loadings 3.43 3.03
## Proportion Var 0.38 0.34
## Cumulative Var 0.38 0.72
## Proportion Explained 0.53 0.47
## Cumulative Proportion 0.53 1.00
##
## Mean item complexity = 1.4
## Test of the hypothesis that 2 components are sufficient.
##
## The root mean square of the residuals (RMSR) is 0.07
## with the empirical chi square 49.8 with prob < 0.00014
##
## Fit based upon off diagonal values = 0.98Die Anteil Varianz (Proportion Var) zeigt, dass mit der Komponente 1 (RC1) 38 Prozent der Streuung erklärten werde kann und mit der Komponente 2 (RC2) 34 Prozent. Insgesamt können somit mit zwei Komponenten (Anstatt 9 Items) immer noch 72 Prozent der Streuung erklärt werden. Eine Dimensionsreduktion ist nur sinnvoll durchzuführen, wenn durch die Komponenten mindestens 50 Prozent der Streuung erklärt werden kann.
Merke: Ziel der Dimensionsreduktion ist immer die Variablen auf so wenig wie möglich Komponenten zu reduzieren aber gleichzeitig so viel Streuung wie möglich zu erklären.
Die Zahlen unter RC1 und RC2 nennt man Ladungen. Eine Ladung ist die Korrelation zur Komponente.
Achtung: Anpassung der PCA durch Wegnahme von V3_7, weil Korrelation (Ladung) zu RC1 0,46 und zu RC2 0,53. D.h. die Variable lädt auf zwei Komponenten ungefähr gleich schwach (Doppelladung). Man sieht auch im corrplot, das V3_7 mit keiner anderen Variable richtig korreliert. Optimal sind Ladungen größer 0,7. Ab 0,5 geht aber auch, abhängig vom Kontext.
Deswegen wiederholen wir die PCA (Idealerweise sogar den Screeplot):
VSS.scree(data[c(1:6,8:9)])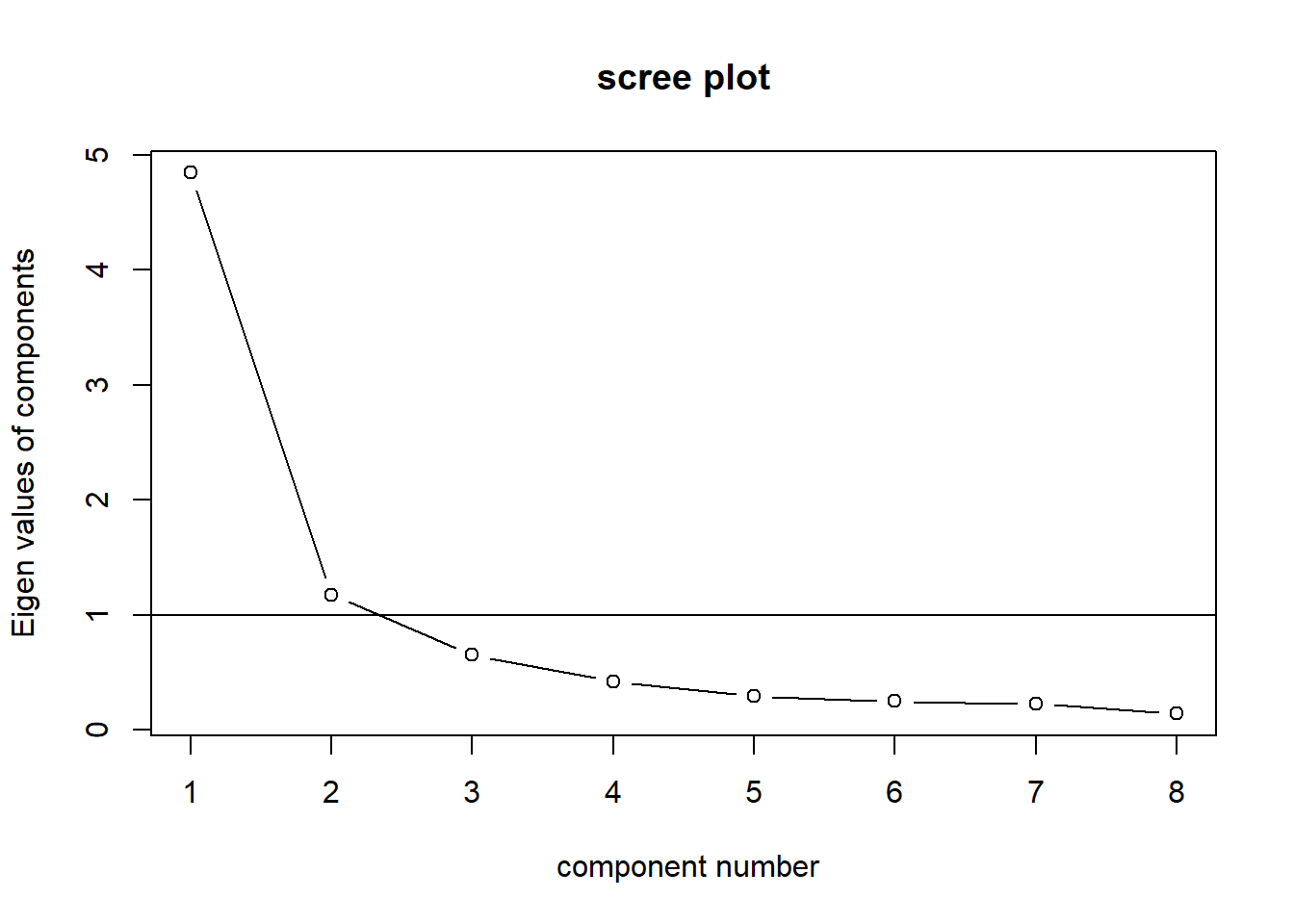
pca<-principal(data[c(1:6,8:9)], 2) # hier nicht vergessen die Anzahl Komponenten einzutragen
print(pca, cut=0.6, sort=TRUE)## Principal Components Analysis
## Call: principal(r = data[c(1:6, 8:9)], nfactors = 2)
## Standardized loadings (pattern matrix) based upon correlation matrix
## item RC1 RC2 h2 u2 com
## V3_8 7 0.90 0.81 0.19 1.0
## V3_4 4 0.83 0.71 0.29 1.1
## V3_9 8 0.74 0.75 0.25 1.6
## V3_5 5 0.73 0.81 0.19 1.8
## V3_6 6 0.70 0.71 0.29 1.8
## V3_2 2 0.88 0.78 0.22 1.0
## V3_1 1 0.83 0.76 0.24 1.2
## V3_3 3 0.75 0.69 0.31 1.4
##
## RC1 RC2
## SS loadings 3.27 2.75
## Proportion Var 0.41 0.34
## Cumulative Var 0.41 0.75
## Proportion Explained 0.54 0.46
## Cumulative Proportion 0.54 1.00
##
## Mean item complexity = 1.4
## Test of the hypothesis that 2 components are sufficient.
##
## The root mean square of the residuals (RMSR) is 0.07
## with the empirical chi square 42 with prob < 6.5e-05
##
## Fit based upon off diagonal values = 0.98Ergebnis der PCA: von den 9 Items lassen sich 8 Items auf 2 Komponenten verdichten. Die kummulierte Varianzist 0,75, also größer 0,5.
Zum Schluss wird noch die Reliabilität der Komponenten geprüft. Die Reliabilität der Konstrukte wird durch das Cronbach’s Alpha geprüft. => Güteprüfung: Wenn möglich Alpha > 0,7
6.3 Was ist ein Cronbach’s Alpha?
6.3.1 Interne Konsistenz der Skalen
Das einfachste Maß für die interne Konsistenz ist die Split-Half-Reliabilität. Die Items werden in zwei Hälften unterteilt und die resultierenden Scores sollten in ihren Kenngrößen ähnlich sein. Hohe Korrelationen zwischen den Hälften deuten auf eine hohe interne Konsistenz hin. Das Problem ist, dass die Ergebnisse davon abhängen, wie die Items aufgeteilt werden. Ein üblicher Ansatz zur Lösung dieses Problems besteht darin, den Koeffizienten Alpha (Cronbachs Alpha) zu verwenden.
6.3.2 Cronbachs Alpha
Der Koeffizient Alpha ist der Mittelwert aller möglichen Split-Half-Koeffizienten, die sich aus verschiedenen Arten der Aufteilung der Items ergeben. Dieser Koeffizient variiert von 0 bis 1. Formal ist es ein korrigierter durchschnittlicher Korrelationskoeffizient. Zufriedenstellende Reliabilität wird bei einem Alpha-Wert von 0.7 erreicht. Werte unter 0.5 gelten als nicht akzeptabel, Werte ab 0.8 als gut.
cronbach.alpha(data[1:3]) ##
## Cronbach's alpha for the 'data[1:3]' data-set
##
## Items: 3
## Sample units: 134
## alpha: 0.83cronbach.alpha(data[c(4:6,8,9)]) ##
## Cronbach's alpha for the 'data[c(4:6, 8, 9)]' data-set
##
## Items: 5
## Sample units: 134
## alpha: 0.904Ergebnis: Beide Alphas sind gut.
Wann wird ein Item aus der weiteren Analyse ausgeschlossen? Antwort: Wenn das Alpha unter dem gewünschtem Schwellenwert liegt.
Fragestellung: Lassen sich die Komponenten gut inhaltlich interpretieren, und wie sollen Komponenten heißen?
RC1 kann zusammengefasst werden als Erschöpfung und RC2 als Stress
6.3.3 Bildung der Hauptkomponenten Erschöpfung und Stress
Über rowMeans wird der Mittelwert pro Person über die ausgewählten Variablen gebildet und in einer neuen Variablen gespeichert. Damit erweitert sich der Datensatz um zwei neue Variablen (unsere gebildeten Komponenten). Alles, was davor analysiert wurde, dient nur dazu, zu erfahren, welche Variablen (Items) zu welchen Komponenten (Konstrukten) zusammengefasst werden können.
data$Erschoepft<-rowMeans(data[1:3], na.rm = TRUE)
data$Stress<-rowMeans(data[c(4:6,8,9)], na.rm = TRUE)
t(colnames(data))## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
## [1,] "V3_1" "V3_2" "V3_3" "V3_4" "V3_5" "V3_6" "V3_7" "V3_8" "V3_9"
## [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17]
## [1,] "Berufliche.Belastung" "V9_1" "V9_2" "V9_3" "V9_4" "V10_1" "V10_2" "V10_3"
## [,18] [,19] [,20] [,21] [,22] [,23]
## [1,] "V10_4" "V10_5" "V10_6" "Geschlecht" "Bildungsabschluss" "Erschoepft"
## [,24]
## [1,] "Stress"Umbenennung von Variablen
data$Erschoepfung<-data$Erschoepft #Variable unter neuem Namen speichern
data$Erschoepft<-NULL # Alte Variable löschen
t(colnames(data))## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
## [1,] "V3_1" "V3_2" "V3_3" "V3_4" "V3_5" "V3_6" "V3_7" "V3_8" "V3_9"
## [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17]
## [1,] "Berufliche.Belastung" "V9_1" "V9_2" "V9_3" "V9_4" "V10_1" "V10_2" "V10_3"
## [,18] [,19] [,20] [,21] [,22] [,23]
## [1,] "V10_4" "V10_5" "V10_6" "Geschlecht" "Bildungsabschluss" "Stress"
## [,24]
## [1,] "Erschoepfung"#oder so wie oben:
#names(data)[24] <- c("Erschoepfung")6.3.4 Überprüfung der Struktur für Gesundheit und Bildung des Konstrukts
t(colnames(data))## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
## [1,] "V3_1" "V3_2" "V3_3" "V3_4" "V3_5" "V3_6" "V3_7" "V3_8" "V3_9"
## [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17]
## [1,] "Berufliche.Belastung" "V9_1" "V9_2" "V9_3" "V9_4" "V10_1" "V10_2" "V10_3"
## [,18] [,19] [,20] [,21] [,22] [,23]
## [1,] "V10_4" "V10_5" "V10_6" "Geschlecht" "Bildungsabschluss" "Stress"
## [,24]
## [1,] "Erschoepfung"corrplot(cor(data[11:20]), order="hclust")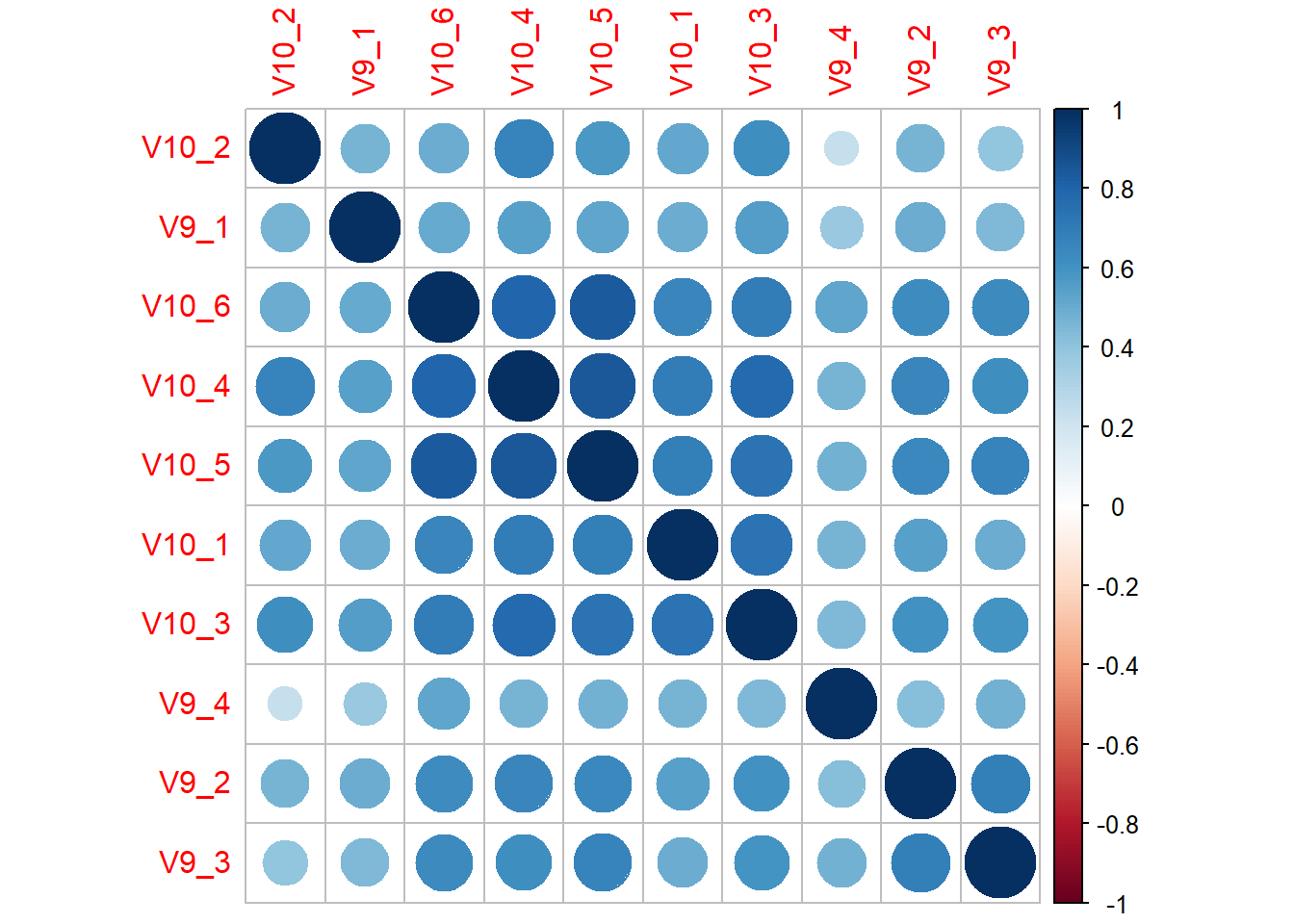
VSS.scree(data[11:20])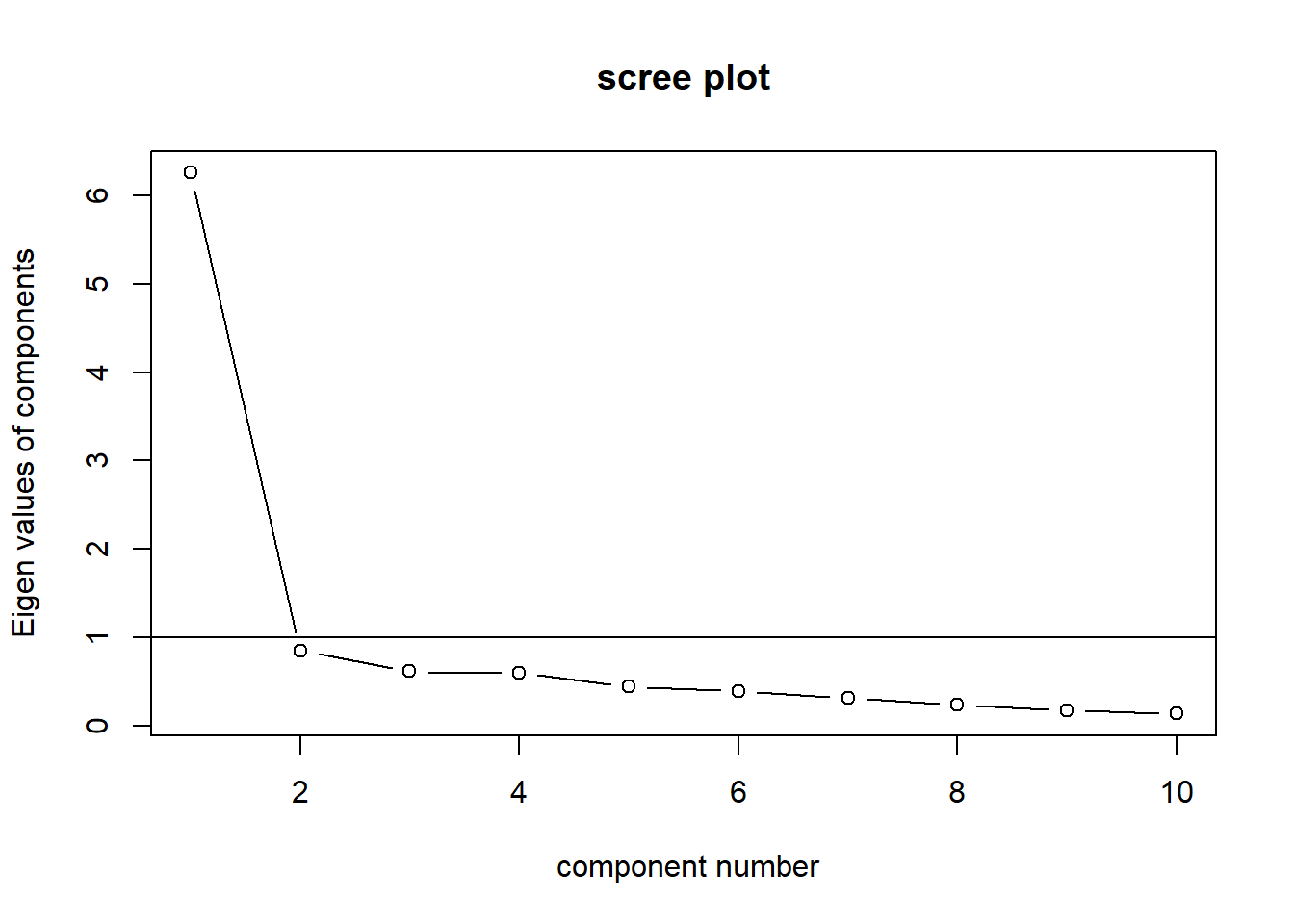
pca<-principal(data[11:20], 1) # hier nicht vergessen die Anzahl Komponenten einzutragen
print(pca, cut=0.4, sort=TRUE)## Principal Components Analysis
## Call: principal(r = data[11:20], nfactors = 1)
## Standardized loadings (pattern matrix) based upon correlation matrix
## V PC1 h2 u2 com
## V10_4 8 0.91 0.82 0.18 1
## V10_5 9 0.90 0.81 0.19 1
## V10_6 10 0.87 0.76 0.24 1
## V10_3 7 0.86 0.74 0.26 1
## V10_1 5 0.80 0.65 0.35 1
## V9_2 2 0.78 0.61 0.39 1
## V9_3 3 0.76 0.58 0.42 1
## V10_2 6 0.69 0.47 0.53 1
## V9_1 1 0.68 0.46 0.54 1
## V9_4 4 0.60 0.36 0.64 1
##
## PC1
## SS loadings 6.26
## Proportion Var 0.63
##
## Mean item complexity = 1
## Test of the hypothesis that 1 component is sufficient.
##
## The root mean square of the residuals (RMSR) is 0.06
## with the empirical chi square 49.61 with prob < 0.052
##
## Fit based upon off diagonal values = 0.99cronbach.alpha(data[c(11:20)]) ##
## Cronbach's alpha for the 'data[c(11:20)]' data-set
##
## Items: 10
## Sample units: 134
## alpha: 0.931data$Gesundheit<-rowMeans(data[11:20], na.rm = TRUE)
t(colnames(data))## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
## [1,] "V3_1" "V3_2" "V3_3" "V3_4" "V3_5" "V3_6" "V3_7" "V3_8" "V3_9"
## [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17]
## [1,] "Berufliche.Belastung" "V9_1" "V9_2" "V9_3" "V9_4" "V10_1" "V10_2" "V10_3"
## [,18] [,19] [,20] [,21] [,22] [,23]
## [1,] "V10_4" "V10_5" "V10_6" "Geschlecht" "Bildungsabschluss" "Stress"
## [,24] [,25]
## [1,] "Erschoepfung" "Gesundheit"7 Voraussetzung für eine barrierefreie Datenanalyse.
=> alle Schritte bis hierher durchführen:
- Die Daten müssen richtig klassifiziert sein.
- Die Konstrukte müssen über z. B. Mittelwertbildung gebildet sein.
8 Daten skalieren.
=> Verweis auf Skript Dimensionsreduktion
Der Befehl lautet scale(). Mit dem Befehl kann entweder einen ganze Datenmatrix oder nur eine Auswahl von Variablen skaliert werden. Dies ist dann notwendig, wenn Daten unterschiedlich skaliert sind.
9 Grundlagen der Inferenzstatistik (Kurze Wiederholung aus dem Studium: Was ist wirklich relevant, um die Inferenz zu verstehen!
Was ist ein p-value?
p-value = Wahrscheinlichkeit für die Teststatistik (standardisierter Mittelwert) unter Annahme der Nullhypothese.
Forschungshypothese: Mein Untersuchungsgegenstand Nullhypothese: Es gibt keinen Effekt!
Wichtig: Es gibt 5 Signifikanzniveaus:
- n.s.: Nicht signifikant
- 0,10: Zum 10 Prozent Niveau signifikant
- 0,05: zum 5 Prozent Niveau signifikant
- 0,01: zum 1 Prozent Niveau signifikant
- 0,001: zum 0,1 Prozent Niveau signifikant
Achtung: Signifikanz heißt nicht Repräsentativität!!!!
Wichtig: Niemals in der Abschlussarbeit/Seminararbeit/Hausarbeit/Essay die H0 erwähnen, immer nur die Forschungshypothesen.
9.1 Test auf Normalverteilung
Test für alle drei Konstrukte
shapiro.test(data$Stress)##
## Shapiro-Wilk normality test
##
## data: data$Stress
## W = 0.89833, p-value = 4.38e-08shapiro.test(data$Erschoepfung)##
## Shapiro-Wilk normality test
##
## data: data$Erschoepfung
## W = 0.96559, p-value = 0.001811shapiro.test(data$Gesundheit)##
## Shapiro-Wilk normality test
##
## data: data$Gesundheit
## W = 0.95636, p-value = 0.0002858Alle Konstrukte sind signifikant nicht normalverteilt. Macht nix, ist normal! 😊
Wir verwenden den zentralen Grenzwertsatz. Der lautet: Wenn n>30, dann gehen wir von normalverteilten Daten aus. Das ist OK so und legitim.
9.2 Korrelationstest
corr.test(data$Stress, data$Gesundheit)## Call:corr.test(x = data$Stress, y = data$Gesundheit)
## Correlation matrix
## [1] 0.77
## Sample Size
## [1] 134
## These are the unadjusted probability values.
## The probability values adjusted for multiple tests are in the p.adj object.
## [1] 0
##
## To see confidence intervals of the correlations, print with the short=FALSE optionschöner
data[,c("Stress", "Gesundheit")]%>%
chart.Correlation()## Warning in par(usr): argument 1 does not name a graphical parameter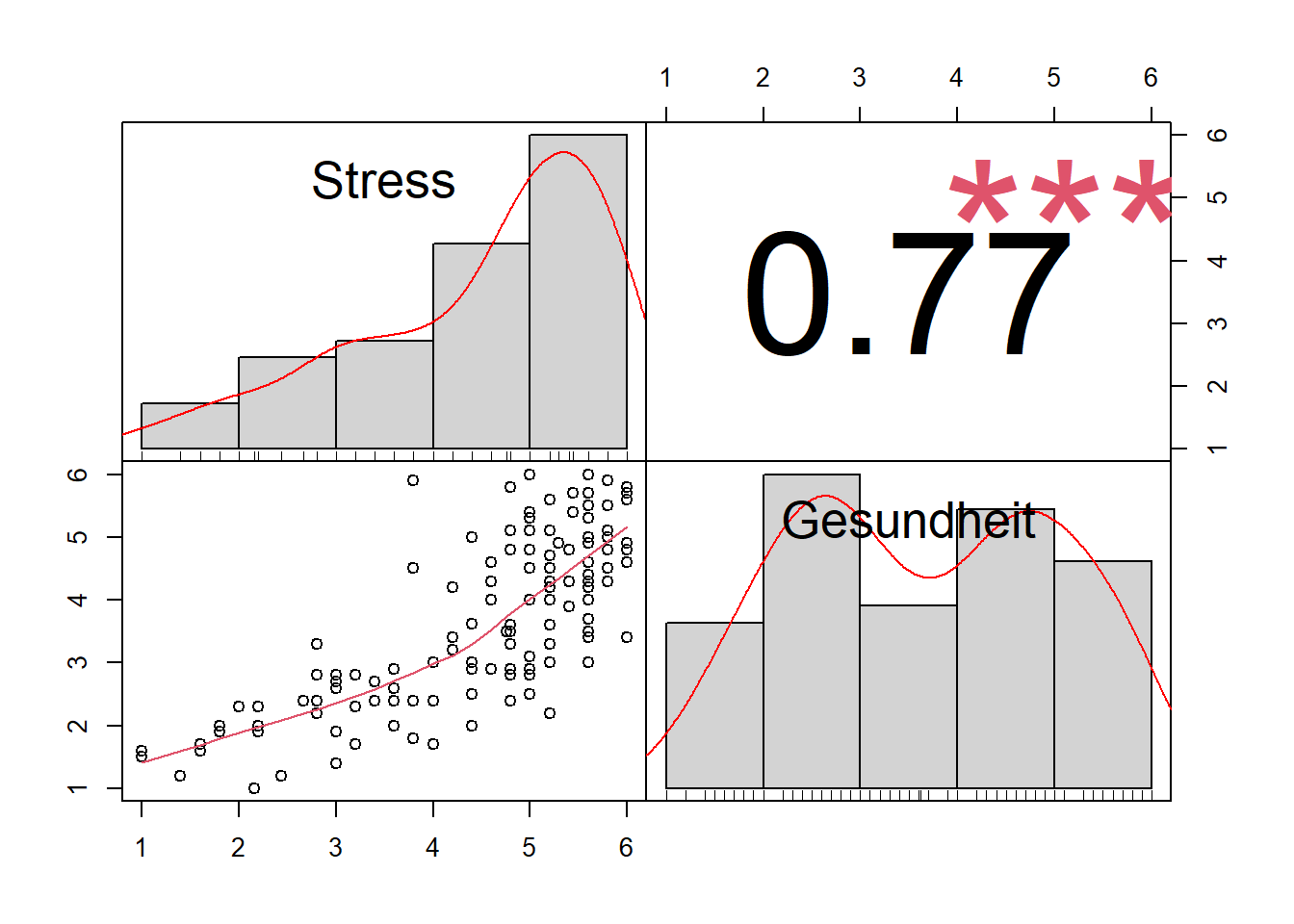
9.3 Lineare multiple Regressionsanalyse
Forschungshypothese: Stress und Erschöpfung hat haben einen negativen Einfluss auf Gesundheit. (Achtung: Auf die Skalierung und die Richtung der Werte in den Daten bezüglich der Bedeutung achten!)
Anwendung: Bei der linearen Regressionsanalyse wird der Einfluss einer metrischen oder kategorialen unabhängige Variablen auf eine metrische abhängige Variable geprüft.
Wird oft als Hypothese so formuliert: Wenn….dann… Bsp.: wenn Stress, dann ungesund.
model<-lm(Gesundheit~Stress , data=data)
summary(model)##
## Call:
## lm(formula = Gesundheit ~ Stress, data = data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.04545 -0.59028 0.03042 0.63139 2.78903
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.03169 0.27463 0.115 0.908
## Stress 0.81034 0.05880 13.780 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8654 on 132 degrees of freedom
## Multiple R-squared: 0.5899, Adjusted R-squared: 0.5868
## F-statistic: 189.9 on 1 and 132 DF, p-value: < 2.2e-16model<-lm(Gesundheit~Erschoepfung, data=data)
summary(model)##
## Call:
## lm(formula = Gesundheit ~ Erschoepfung, data = data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.7573 -0.5461 -0.1234 0.5827 3.1190
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.92081 0.21518 4.279 3.57e-05 ***
## Erschoepfung 0.81612 0.05978 13.652 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8702 on 132 degrees of freedom
## Multiple R-squared: 0.5854, Adjusted R-squared: 0.5823
## F-statistic: 186.4 on 1 and 132 DF, p-value: < 2.2e-16model<-lm(Gesundheit~Stress + Erschoepfung, data=data)
summary(model)##
## Call:
## lm(formula = Gesundheit ~ Stress + Erschoepfung, data = data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.54165 -0.46541 -0.02126 0.41680 2.32457
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.26846 0.22931 -1.171 0.244
## Stress 0.50230 0.06195 8.108 3.21e-13 ***
## Erschoepfung 0.49945 0.06264 7.974 6.67e-13 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7128 on 131 degrees of freedom
## Multiple R-squared: 0.7239, Adjusted R-squared: 0.7197
## F-statistic: 171.8 on 2 and 131 DF, p-value: < 2.2e-16Ergebnis: Je mehr Stress (ß1=0,50) und je mehr Erschöpfung (ß2=0,50), desto ungesünder (t=8,1, p<0,001 und t=7,9, p<0,001). Mit dem Modell können 72% der Streuung von Gesundheit durch Stress und Erschöpfung erklärt werden.
xyplot(Gesundheit~Stress, data=data)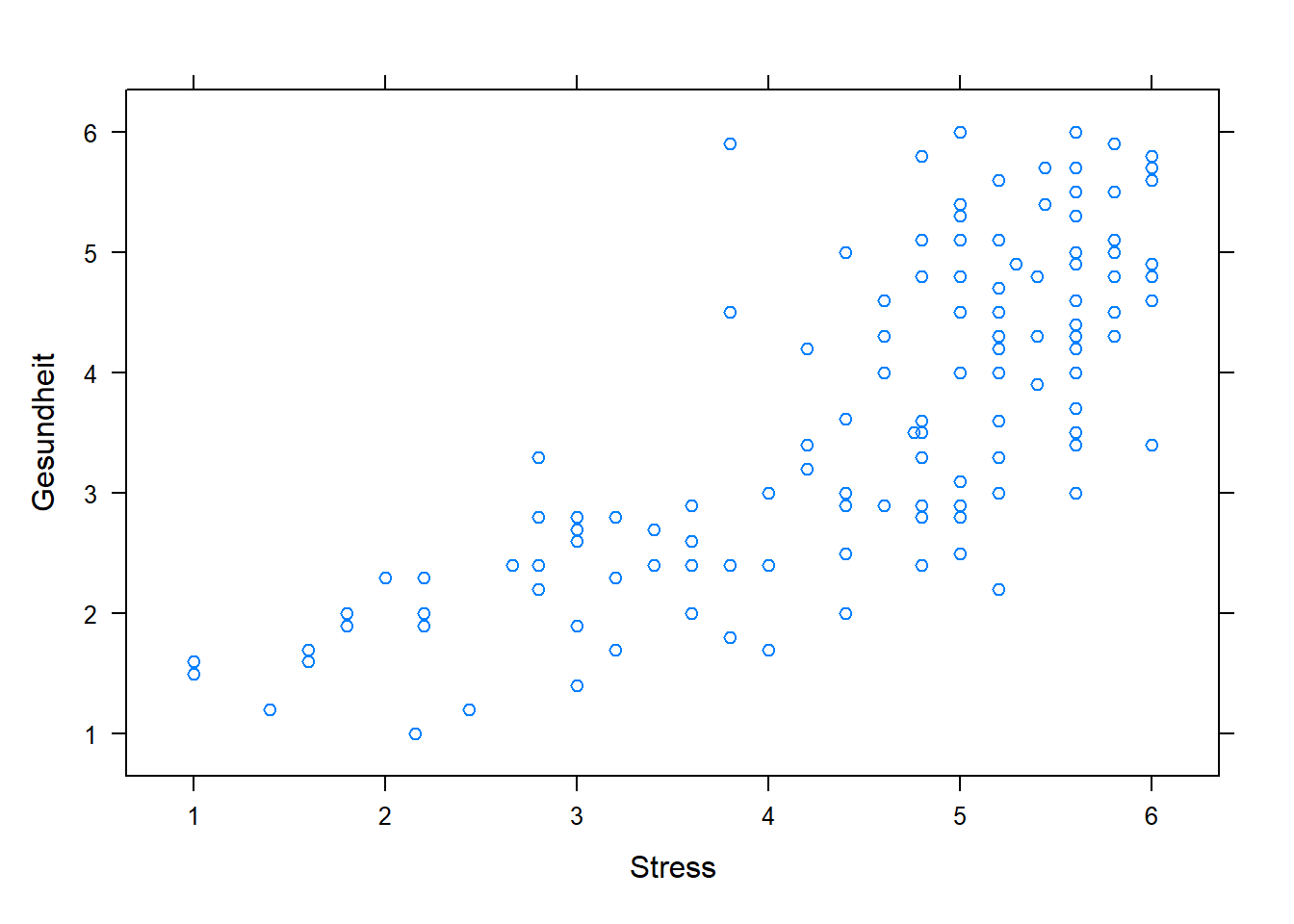
xyplot(Gesundheit~Erschoepfung, data=data)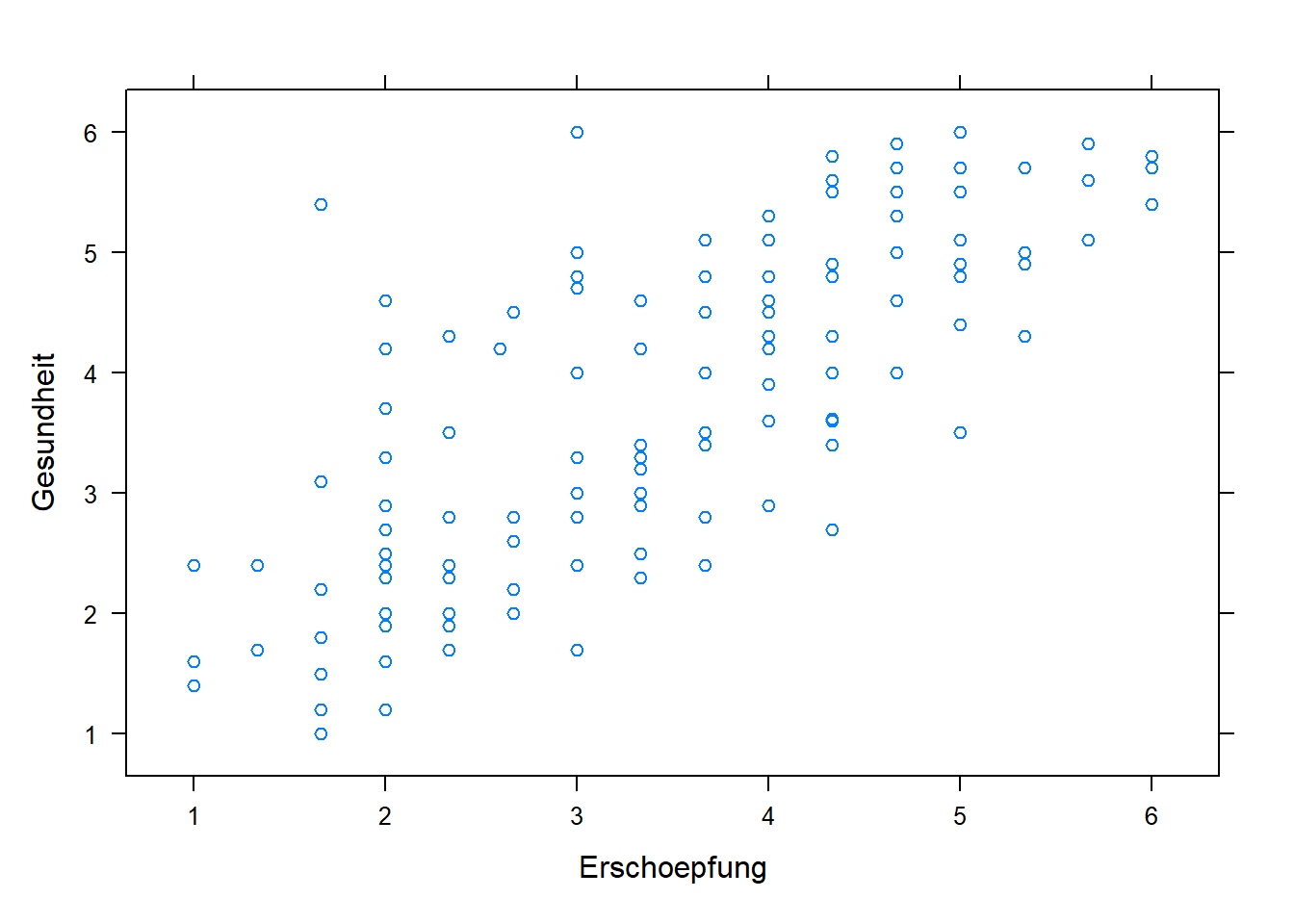
Plot mit einer unabhängigen Variable
model<-lm(Gesundheit~Stress, data=data)
plotModel(model)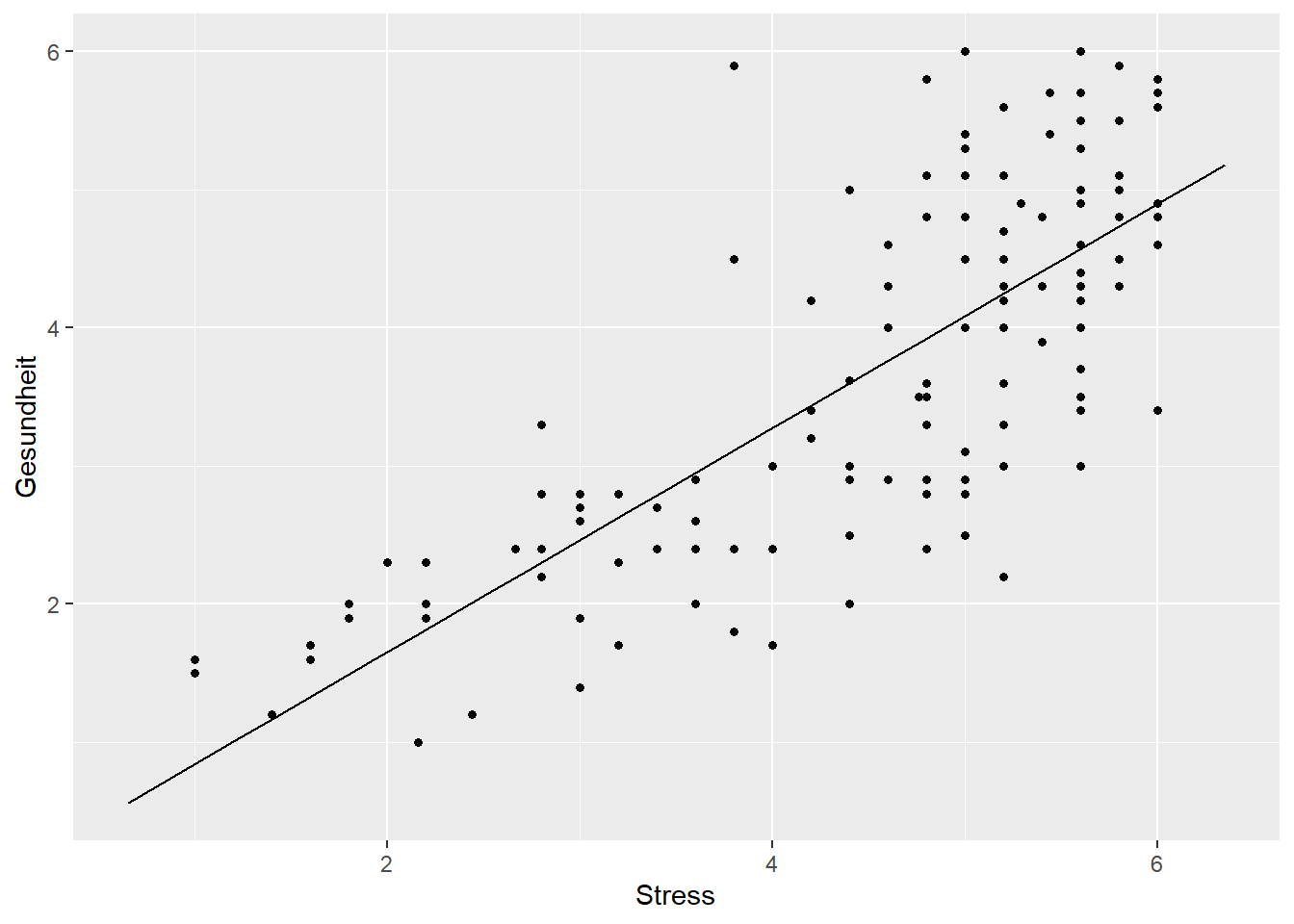
Plot und Tabelle mit dem Paket jtools
library(jtools)
summ(model)| Observations | 134 |
| Dependent variable | Gesundheit |
| Type | OLS linear regression |
| F(1,132) | 189.89 |
| R² | 0.59 |
| Adj. R² | 0.59 |
| Est. | S.E. | t val. | p | |
|---|---|---|---|---|
| (Intercept) | 0.03 | 0.27 | 0.12 | 0.91 |
| Stress | 0.81 | 0.06 | 13.78 | 0.00 |
| Standard errors: OLS |
effect_plot(model, pred = Stress, interval = TRUE, plot.points = TRUE)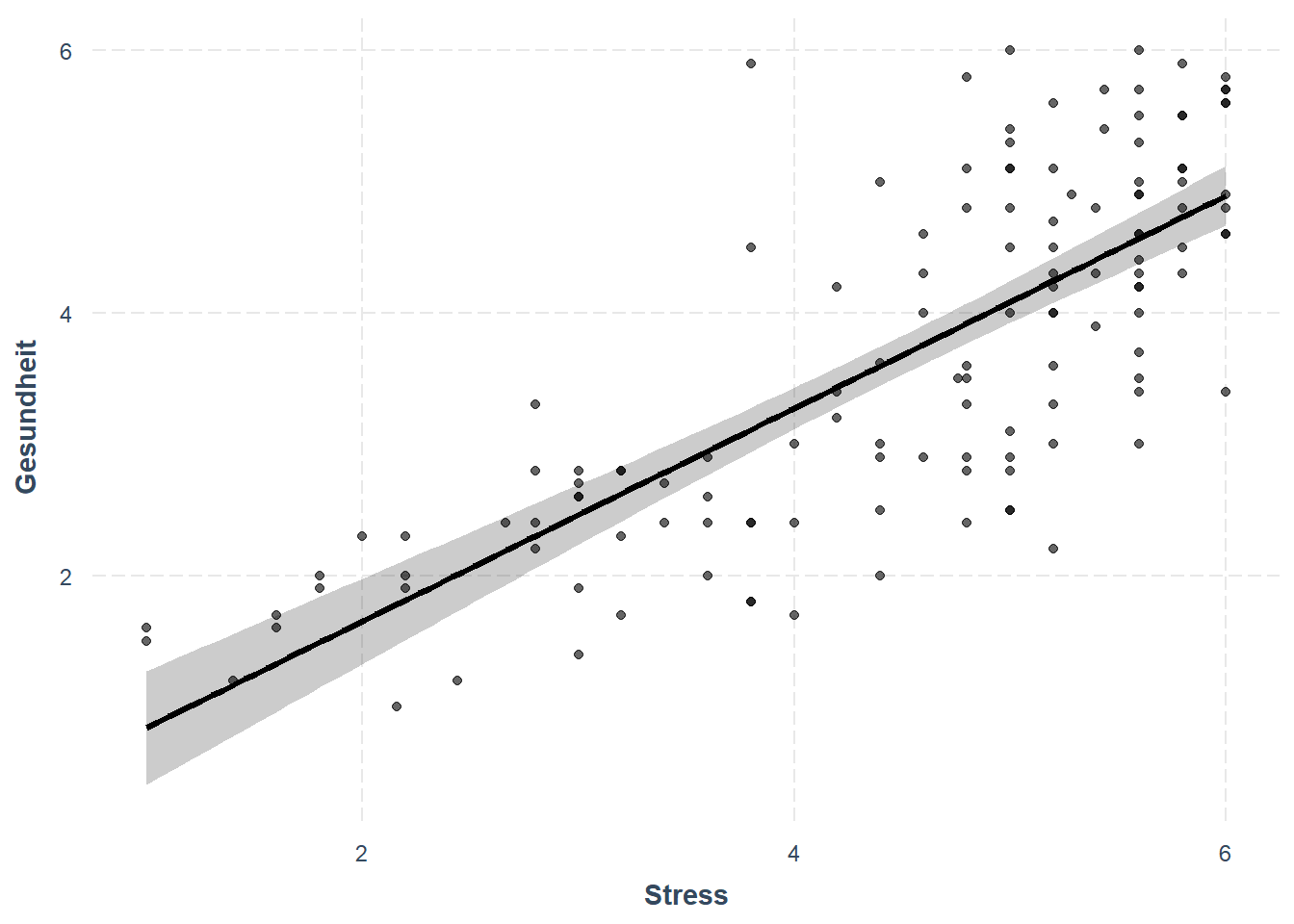
Wie schaut es aus, wenn das Geschlecht noch hinzukomme?
model<-lm(Gesundheit~Stress+Erschoepfung+Geschlecht, data=data)
summ(model)| Observations | 129 (5 missing obs. deleted) |
| Dependent variable | Gesundheit |
| Type | OLS linear regression |
| F(3,125) | 106.11 |
| R² | 0.72 |
| Adj. R² | 0.71 |
| Est. | S.E. | t val. | p | |
|---|---|---|---|---|
| (Intercept) | -0.40 | 0.25 | -1.57 | 0.12 |
| Stress | 0.51 | 0.06 | 7.85 | 0.00 |
| Erschoepfung | 0.49 | 0.06 | 7.73 | 0.00 |
| Geschlechtmännlich | 0.23 | 0.13 | 1.78 | 0.08 |
| Standard errors: OLS |
Geschlecht hat einen signifikanten Einfluss auf Gesundheit zum 10%-Niveau (B3= -0,23, t=-1,78, p<0,10)
Gruppenvergleiche mit dem Paket lme4
library(lme4) # ggf. vorher installieren##
## Attache Paket: 'lme4'## Das folgende Objekt ist maskiert 'package:mosaic':
##
## factorizemodel<-lmList(Gesundheit~Stress | Geschlecht, data=data)
summary(model)## Call:
## Model: Gesundheit ~ Stress | NULL
## Data: data
##
## Coefficients:
## (Intercept)
## Estimate Std. Error t value Pr(>|t|)
## weiblich -0.05087521 0.4987363 -0.1020082 0.9189136
## männlich 0.06092697 0.3561721 0.1710605 0.8644528
## Stress
## Estimate Std. Error t value Pr(>|t|)
## weiblich 0.7895310 0.10558193 7.477899 1.159735e-11
## männlich 0.8306924 0.07654056 10.852970 9.692046e-20
##
## Residual standard error: 0.8708456 on 125 degrees of freedomInteraktionseffekte
model<-lm(Gesundheit~Stress+ Stress:Geschlecht, data=data)
summ(model)| Observations | 129 (5 missing obs. deleted) |
| Dependent variable | Gesundheit |
| Type | OLS linear regression |
| F(2,126) | 88.23 |
| R² | 0.58 |
| Adj. R² | 0.58 |
| Est. | S.E. | t val. | p | |
|---|---|---|---|---|
| (Intercept) | 0.02 | 0.29 | 0.08 | 0.94 |
| Stress | 0.77 | 0.06 | 12.05 | 0.00 |
| Stress:Geschlechtmännlich | 0.06 | 0.03 | 1.96 | 0.05 |
| Standard errors: OLS |
plotModel(model)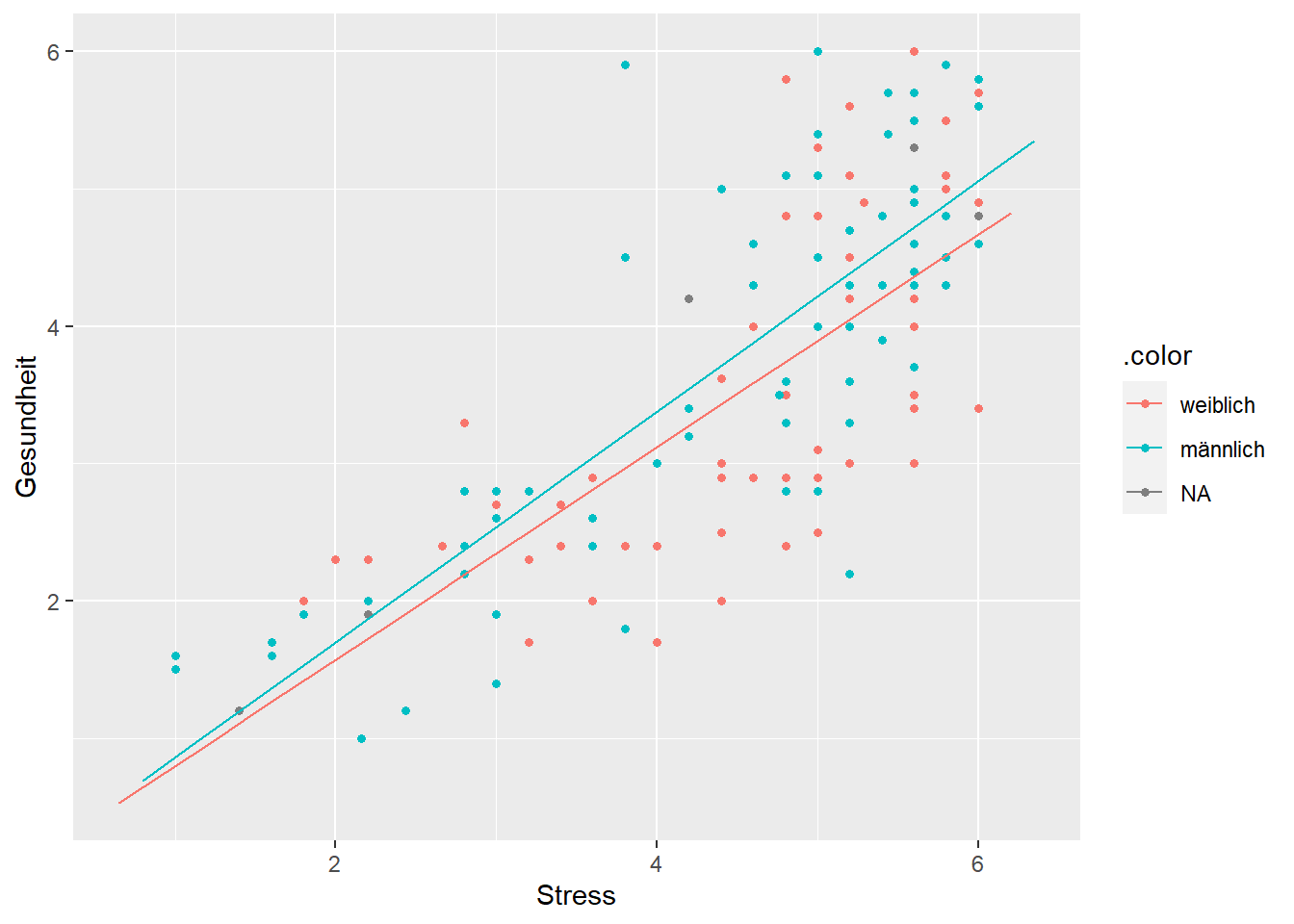
levels(data$Bildungsabschluss)## [1] "Fachhochschule" "Hochschule"
## [3] "Keinen akademischen Abschluss" "Uni"model<-lmList(Gesundheit~Stress|Bildungsabschluss, data=data)
summary(model)## Call:
## Model: Gesundheit ~ Stress | NULL
## Data: data
##
## Coefficients:
## (Intercept)
## Estimate Std. Error t value Pr(>|t|)
## Fachhochschule -0.1355385 0.5614983 -0.2413872 0.8096537
## Hochschule 0.3811300 0.7670676 0.4968662 0.6201632
## Keinen akademischen Abschluss -0.3081860 0.5733522 -0.5375160 0.5918745
## Uni 0.3553268 0.4850781 0.7325147 0.4652369
## Stress
## Estimate Std. Error t value Pr(>|t|)
## Fachhochschule 0.8467248 0.1170736 7.232417 4.302119e-11
## Hochschule 0.7628699 0.1674182 4.556674 1.226741e-05
## Keinen akademischen Abschluss 0.8465791 0.1293272 6.546027 1.405778e-09
## Uni 0.7597060 0.1003981 7.566936 7.499830e-12
##
## Residual standard error: 0.8823309 on 124 degrees of freedomSignifikanztest zwischen zwei Gruppen bezüglich einer metrischen Variable:
Hier: Unterscheidet sich der Stress von Hochschülern signifikant von Universitätsabgängern in Bezug auf den Einfluss auf die Gesundheit
library(car)## Lade nötiges Paket: carData##
## Attache Paket: 'car'## Das folgende Objekt ist maskiert 'package:psych':
##
## logit## Die folgenden Objekte sind maskiert von 'package:mosaic':
##
## deltaMethod, logit## Das folgende Objekt ist maskiert 'package:dplyr':
##
## recodemodel<-lm(Gesundheit~Stress+Stress:Bildungsabschluss, data=data)
linearHypothesis(model, c("Stress:BildungsabschlussUni=Stress:BildungsabschlussHochschule"))## Linear hypothesis test
##
## Hypothesis:
## - Stress:BildungsabschlussHochschule + Stress:BildungsabschlussUni = 0
##
## Model 1: restricted model
## Model 2: Gesundheit ~ Stress + Stress:Bildungsabschluss
##
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 128 97.402
## 2 127 97.375 1 0.027105 0.0354 0.85129.4 t-Tests
t Test (für unabhängige Stipo): Wenn zwei Gruppen, und Unterschied in metrischer Variablen getestet werden soll.
Forschungshypothese: Männer sind ungesünder als Frauen
- deskriptiv
favstats(Gesundheit~Geschlecht, data=data)## Geschlecht min Q1 median Q3 max mean sd n missing
## 1 weiblich 1.7 2.5 3.1 4.800 6 3.57751 1.263368 57 0
## 2 männlich 1.0 2.6 4.0 4.825 6 3.76250 1.389846 72 0- explorativ
gf_boxplot(Gesundheit~Geschlecht, data=data)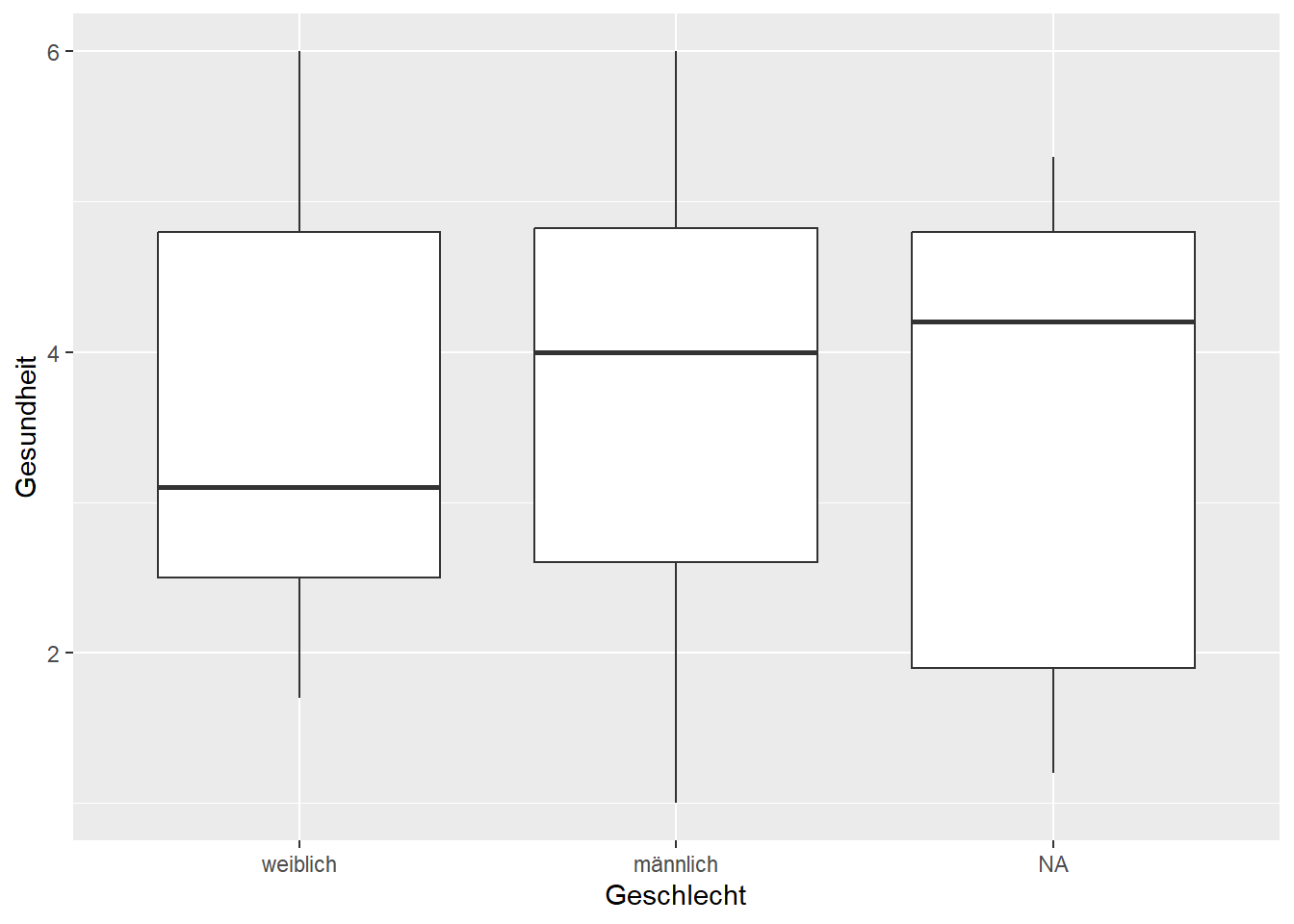
- t.test
Mit dem t-test wird die Signifikanz zwischen zwei Mittelwerten aus einer kategorialen Variablen mit zwei Ausprägungen untersucht.
Männer = Faktor 1 und Frauen = Faktor 2, R bildet immer die Differenz: 1-2, also sollte der Wert bei Männern größer sein.
levels(data$Geschlecht)## [1] "weiblich" "männlich"t.test(Gesundheit~Geschlecht, alternative = "greater", data=data) # "less" für kleiner##
## Welch Two Sample t-test
##
## data: Gesundheit by Geschlecht
## t = -0.79002, df = 124.54, p-value = 0.7845
## alternative hypothesis: true difference in means between group weiblich and group männlich is greater than 0
## 95 percent confidence interval:
## -0.5730345 Inf
## sample estimates:
## mean in group weiblich mean in group männlich
## 3.57751 3.76250Ergebnis: Männer sind nicht gesünder als Frauen (t = 0,79, n.s.)
t-Test für gepaarte Stipo macht nur Sinn bei Vorher-Nachher Befragungen (z. B. bei Zufriedenheitsanalysen). Die Variable für den Test ist dann immer eine Differenz.
t.test(~(V1-V2), alternative = “greater”, data=data)
Was machen wir, wenn es mehr als zwei kategoriale Ausprägungen in der kategorialen Variablen gibt?
9.5 Einfaktorielle Varianzanalyse (ANOVA)
Mit der Varianzanalyse (ANOVA) wird die Signifikanz zwischen mehr als zwei Mittelwerten aus einer kategorialen Variablen mit mehr als zwei Ausprägungen untersucht.
Forschungshypothese: Es gibt einen Unterschied in der Gesundheit, je nach Abschluss. oder genauer: Mindestens eine Gruppe unterscheidet sich von den anderen Gruppen.
favstats(Gesundheit~Bildungsabschluss, data=data)## Bildungsabschluss min Q1 median Q3 max mean sd n
## 1 Fachhochschule 1.2 2.775 3.85 4.65 6.0 3.765625 1.356135 32
## 2 Hochschule 1.7 2.425 3.45 5.25 5.6 3.707143 1.440867 14
## 3 Keinen akademischen Abschluss 1.2 2.350 2.85 4.60 5.6 3.319444 1.292355 36
## 4 Uni 1.0 2.900 4.10 4.90 6.0 3.902361 1.346948 50
## missing
## 1 0
## 2 0
## 3 0
## 4 0gf_boxplot(Gesundheit~Bildungsabschluss, data=data)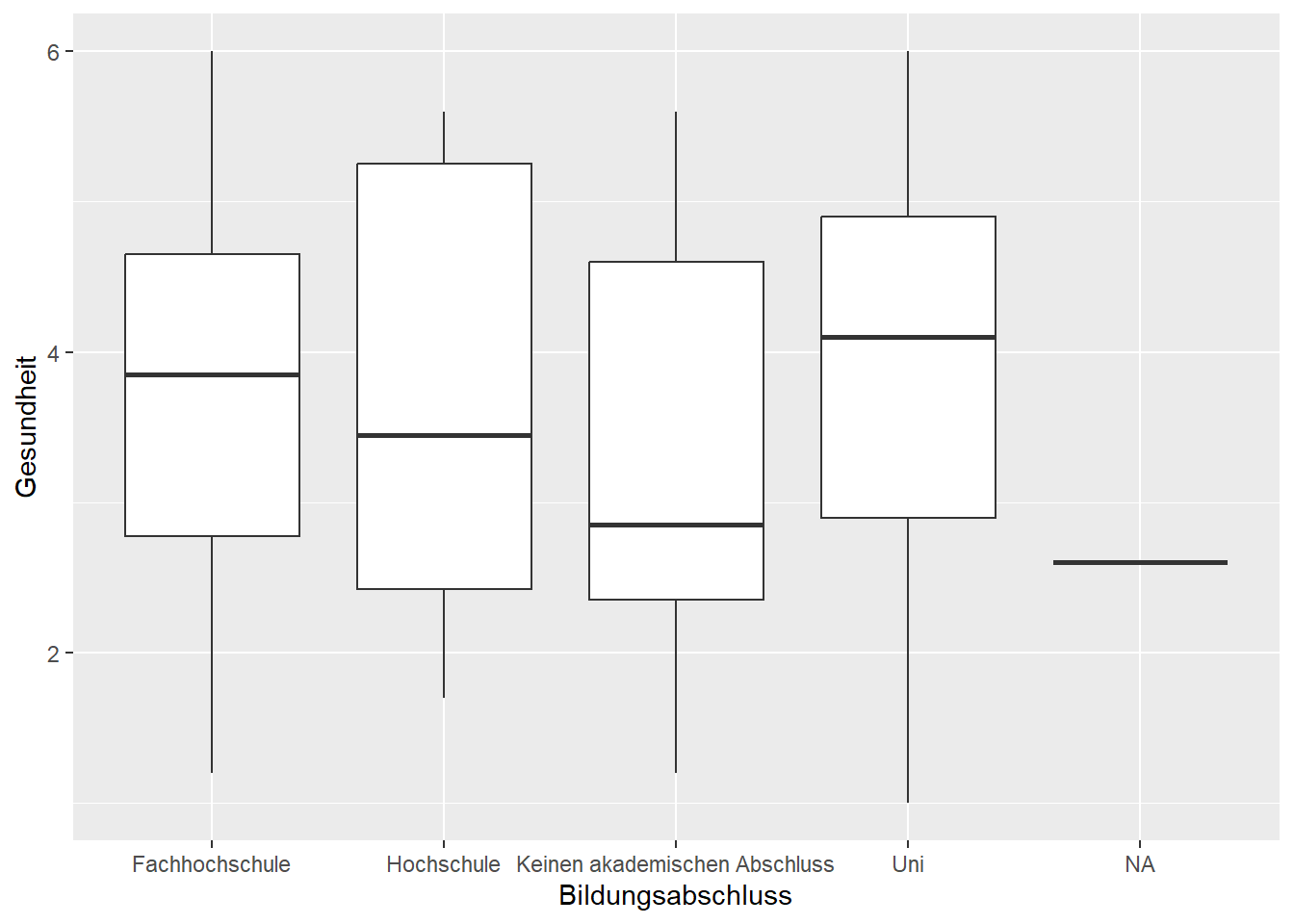
summary(aov(Gesundheit~Bildungsabschluss, data=data))## Df Sum Sq Mean Sq F value Pr(>F)
## Bildungsabschluss 3 7.39 2.462 1.362 0.257
## Residuals 128 231.36 1.808
## 2 Beobachtungen als fehlend gelöschtErgebnis: Keine Gruppe unterscheidet sich signifikant von den anderen (F = 1,36, n.s.)
9.6 Multivariate Varianzanalyse (MANOVA)
summary.aov(manova(cbind(Stress, Erschoepfung)~Bildungsabschluss, data=data))## Response Stress :
## Df Sum Sq Mean Sq F value Pr(>F)
## Bildungsabschluss 3 3.698 1.2328 0.7573 0.5201
## Residuals 128 208.356 1.6278
##
## Response Erschoepfung :
## Df Sum Sq Mean Sq F value Pr(>F)
## Bildungsabschluss 3 2.424 0.80805 0.4962 0.6856
## Residuals 128 208.452 1.62853
##
## 2 Beobachtungen als fehlend gelöscht..und das ganze noch graphisch via Boxplot
library(ggpubr) #ggf. vorher installieren## Registered S3 methods overwritten by 'broom':
## method from
## tidy.glht jtools
## tidy.summary.glht jtoolsdata %>%
na.omit()%>%
ggboxplot(x = "Bildungsabschluss", y = c("Stress", "Erschoepfung"),
merge = TRUE, palette = "jco")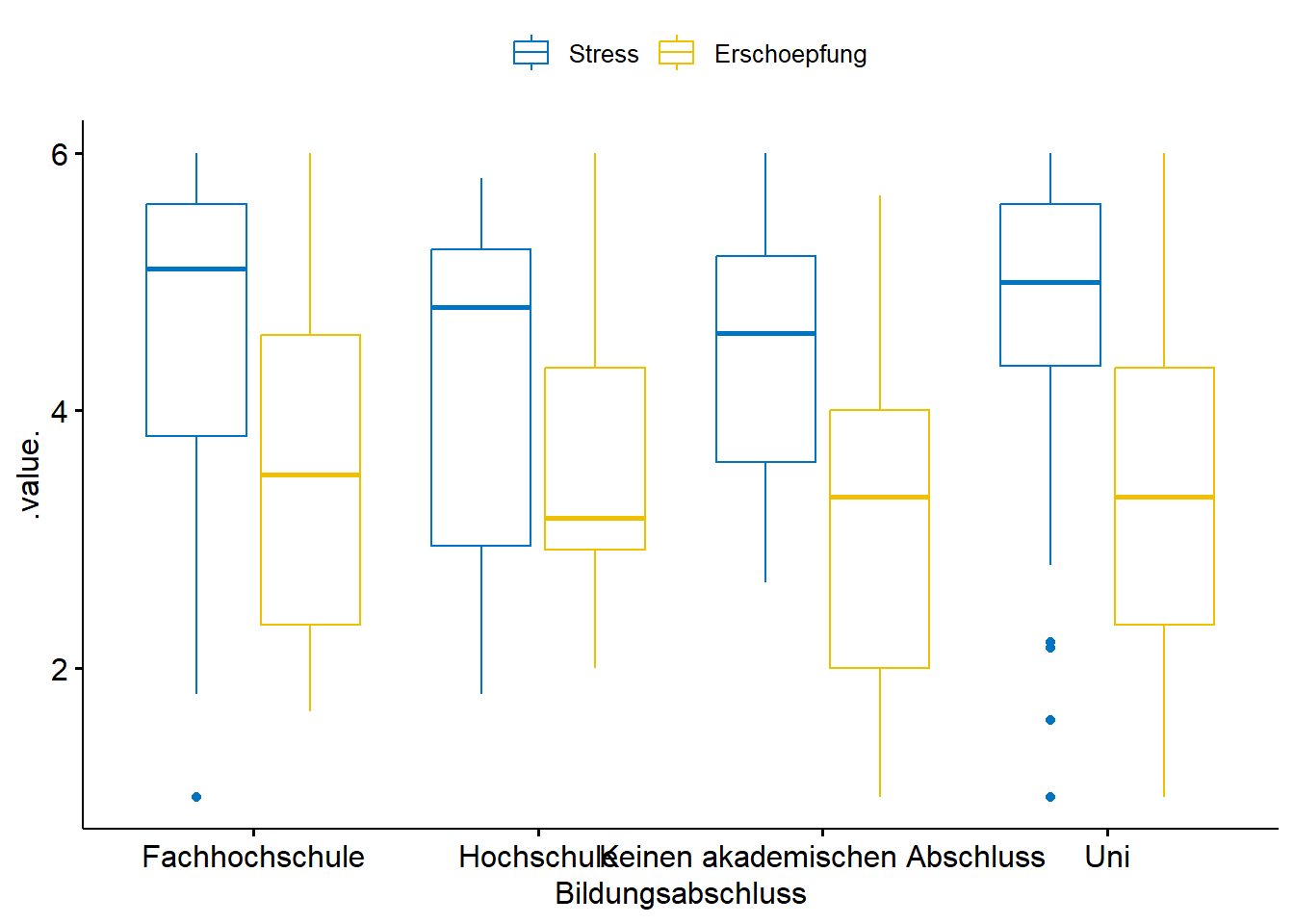
data%>%
na.omit()%>%
ggqqplot("Stress", facet.by = "Bildungsabschluss",
ylab = "", ggtheme = theme_bw())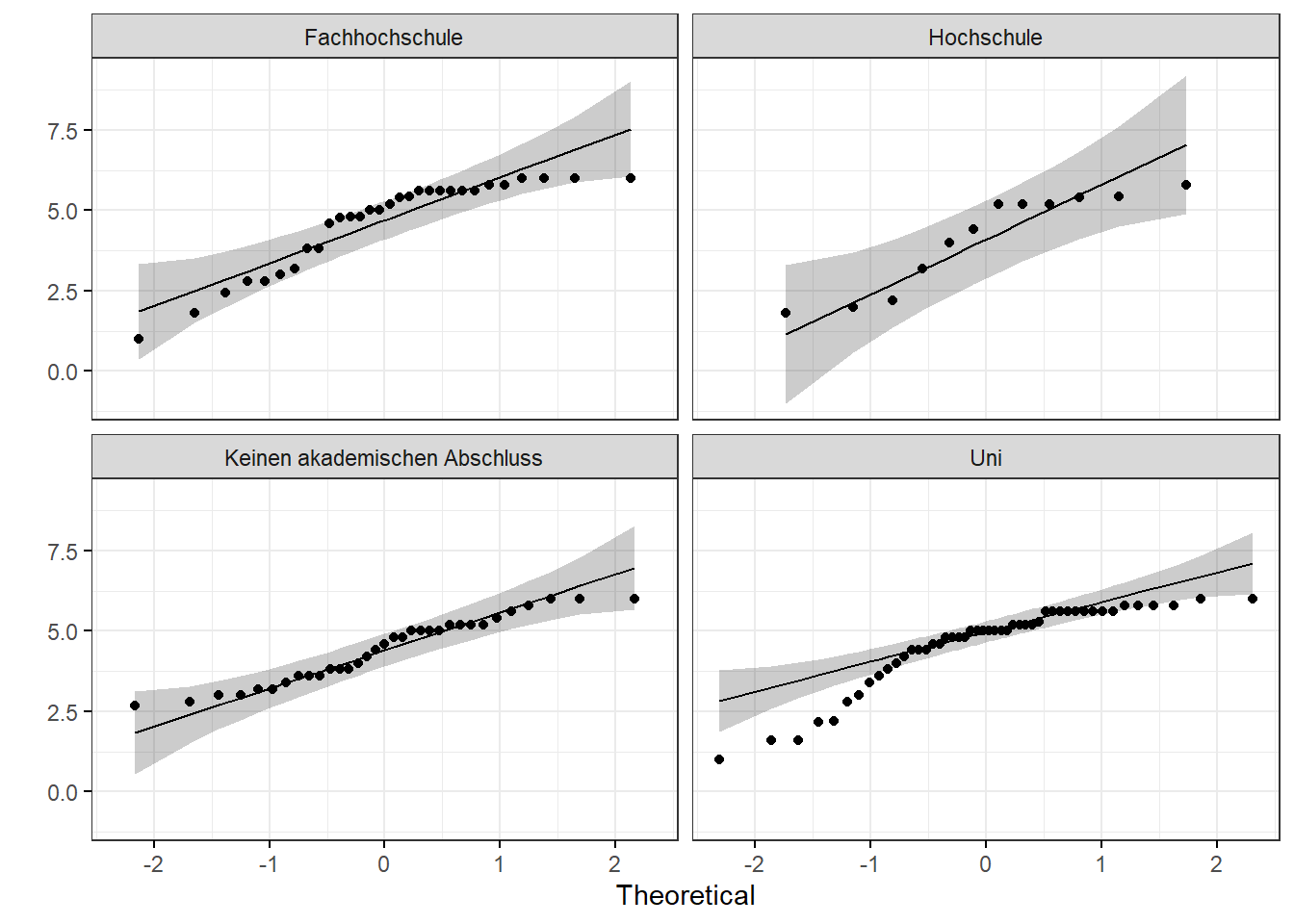
9.7 Post-hoc Test bei der Varianzanalyse
Um nun einzelne t-Tests zwischen den Gruppen durchzuführen, eignet sich der pairwise.t.test. Dies ist allerdings nur sinnvoll, wenn die ANOVA signifikant ist. Dies ist hier nicht der Fall. Aus Veranschaulichungsgründen wird der Post-hoch Test trotzdem durchgeführt.
pairwise.t.test(data$Gesundheit, data$Bildungsabschluss)##
## Pairwise comparisons using t tests with pooled SD
##
## data: data$Gesundheit and data$Bildungsabschluss
##
## Fachhochschule Hochschule
## Hochschule 1.00 -
## Keinen akademischen Abschluss 0.87 1.00
## Uni 1.00 1.00
## Keinen akademischen Abschluss
## Hochschule -
## Keinen akademischen Abschluss -
## Uni 0.30
##
## P value adjustment method: holmWie zu erwarten, sind keine der paarweisen t-Tests signifikant. In der Matrix stehen die p-values der getesteten Vergleichspaare.
9.8 Chi-Quadrat-Unabhängigkeitstest
Chi-Square: Abhängigkeit zwischen zwei nominalen Variablen (Faktor-Variablen).
Forschungsfrage: Gibt es eine Abhängigkeit zwischen Geschlecht und Berufliche Belastung?
Hilfreich ist immer eine Tabelle:
#data<-na.omit(data) # Löschen aller NAs über alle Variablen hinweg
data <- data [!is.na(data$"Geschlecht"), ] # Löschen aller NAs bei Geschlecht
data <- data [!is.na(data$"Berufliche.Belastung"), ] # Löschen aller NAs bei Beruflicher Belastung
Tabelle<-tally(Geschlecht~Berufliche.Belastung, format="percent", data=data)
Tabelle## Berufliche.Belastung
## Geschlecht ja nein
## weiblich 46.98795 35.71429
## männlich 53.01205 64.28571xchisq.test(Tabelle)##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: x
## X-squared = 2.1761, df = 1, p-value = 0.1402
##
## 46.99 35.71
## (41.35) (41.35)
## [0.64] [0.64]
## < 0.88> <-0.88>
##
## 53.01 64.29
## (58.65) (58.65)
## [0.45] [0.45]
## <-0.74> < 0.74>
##
## key:
## observed
## (expected)
## [contribution to X-squared]
## <Pearson residual>Ergebnis: Keine Abhängigkeit zwischen Geschlecht und Berufliche Belastung (Chi-Square = 1,27, n.s.)
9.9 Auf was ist zu achten bei der Fragebogenerstellung (Art der Fragen, Skalierung, etc.)?
Hierzu ist mein Leitfaden hilfreich.
10 Versuchsplanung
10.1 Problemstellung
Die Fragestellung einer Studie ist z. B. der Einfluss der Anzahl Emoticons bei Newslettertexten auf die Wahrnehmung der Empfänger des Newsletters. Hierzu gibt es eine Theorie, dass die Wahrnehmung variiert, abhängig von der Anzahl Emoticons im Text. Da auch der Text einen Einfluss auf die Variation hat, bietet sich für die Untersuchung ein Experimentaldesign an, bei dem der Text kontrolliert wird, d. h. weitestgehend keinen Einfluss hat und die Anzahl Emoticons manipuliert wird.
10.2 Ziel der Versuchsplanung
- Die Elemente eines Versuchsplans sind die Versuchseinheiten und die Behandlungen.
- Die Behandlungen werden den Einheiten zugeordnet
Ziel:
Vergleich der Behandlungen
10.3 Versuchsplanung im Marketing
Im Marketing sind
- die Personen in den verschiedenen Experimentalgruppen die Einheiten.
- die getesteten Maßnahmen die Behandlungen.
10.4 Grundprinzipien der Versuchsplanung
Jede Versuchsplanung basiert auf drei Grundprinzipien:
- Lokale Kontrolle
- Wiederholung
- Randomisierung
10.4.1 Lokale Kontrolle
Bezieht sich auf jede Methode, die natürliche Schwankungen erklärt und reduziert.
Eine Möglichkeit ist die Einteilung ähnlicher Versuchseinheiten in Blöcke.
Im Marketing kann ein Block z. b. eine Werbeanzeige sein, in der verschiedene Behandlungen getestet werden.
10.4.2 Wiederholung
Dieselbe Behandlung wird auf verschiedene Versuchseinheiten angewendet.
Ohne Wiederholung ist es unmöglich, natürliche Schwankungen und Messfehler abzuschätzen
10.4.3 Randomisierung
Randomisierung ist der wesentliche Schritt in jedem statistischen Verfahren. Die Behandlungen müssen den Versuchseinheiten zufällig zugeordnet werden.
10.5 Versuchsplan
Wenn wir die Anzahl Behandlungen unabhängig vom Text untersuchen wollen, müssen wir die Behandlungen mit verschiedenen Texten anbieten. Da wir vier Behandlungen haben, bieten sich auch vier verschiedenen Texte an.
Alle vier Behandlungen werden nun in jedem Text (Block) wiederholt.
Wir nehmen nun die 4 Behandlungen und weisen die Behandlungen nachfolgendem Schema zu.
G = Personengruppen mit Anzahl Emoticons im Text C = Kontrollgruppe E = Experimentalgruppen mit 1,2und 3 Emoticons
| Texte | G1 | G2 | G3 | G4 |
|---|---|---|---|---|
| A | C | E1 | E2 | E3 |
| B | E1 | E2 | E3 | C |
| C | E2 | E3 | C | E1 |
| D | E3 | C | E1 | E2 |
10.6 Lateinisches Quadrat
Eine 4 x 4 Tabelle mit vier verschiedenen Elementen, von denen jedes in einer Zeile und Spalte genau einmal auftritt, heißt Lateinisches Quadrat.
In diesem Experiment erhalten die vier Personengruppe und die vier Texte jede Behandlung genau einmal.
Es gibt somit 4 Experimentalgruppen, die je Text oder auch aggregiert auf Unterschiedlichkeit bezüglich der Wirkung untersucht werden können.
10.7 Die Funktion gather für die Datentransformation bei Experimenten
Wurden für eine experimentelle Versuchsplanung z. B. verschiedene Produkte bei einer Auskunftsperson abgefragt mit denselben Konstrukten, müssen die Daten transponiert werden (oder aus einen breiten einen langen Datensatz machen), so dass eine Variable nur einmal im Datensatz vorkommen, anstatt mehrmals pro Produkt. Die verschiedenen Produkte sind in eine Variable zu packen, die sozusagen eine Produktgruppe (oder einfach nur alle Produkte) darstellt. Die Werte dazu für die Variable muss natürlich hier mitgenommen werden in einer weiteren Spalte.
Wir können dies beispielsweise hier tun mit den drei Variablen Stress, Erschoepfung und Gesundheit und verwenden dazu die Funktion gather:
data%>%
tidyr::gather(key = key, value = value, c("Stress", "Erschoepfung", "Gesundheit") )%>%
head() # zeigt die ersten 6 Zeilen des neuen Datensatzes ## V3_1 V3_2 V3_3 V3_4 V3_5 V3_6 V3_7 V3_8 V3_9 Berufliche.Belastung V9_1 V9_2
## 1 2 2 3 1 1 3 2 2 4 ja 2 1
## 2 5 5 5 6 4 5 5 4 5 nein 5 6
## 3 2 2 3 1 1 2 2 3 1 ja 2 1
## 4 5 2 5 6 6 6 2 6 6 ja 6 6
## 5 3 4 5 6 6 5 3 6 6 nein 5 5
## 6 5 4 4 4 4 3 2 5 5 nein 5 1
## V9_3 V9_4 V10_1 V10_2 V10_3 V10_4 V10_5 V10_6 Geschlecht
## 1 1 1 6 2 2 1 2 2 männlich
## 2 4 5 5 5 6 5 5 5 männlich
## 3 1 2 2 2 2 1 2 2 männlich
## 4 4 2 6 6 5 5 3 3 weiblich
## 5 6 2 6 6 6 4 5 6 männlich
## 6 1 2 4 5 4 4 4 4 männlich
## Bildungsabschluss key value
## 1 Uni Stress 2.2
## 2 Keinen akademischen Abschluss Stress 4.8
## 3 Uni Stress 1.6
## 4 Keinen akademischen Abschluss Stress 6.0
## 5 Uni Stress 5.8
## 6 Uni Stress 4.2data%>%
tidyr::gather(key = key, value = value, c("Stress", "Erschoepfung", "Gesundheit") )%>%
tail() # zeigt die letzten 6 Zeilen des neuen Datensatzes ## V3_1 V3_2 V3_3 V3_4 V3_5 V3_6 V3_7 V3_8 V3_9 Berufliche.Belastung V9_1 V9_2
## 370 3 3 5 2 3 4 2 5 5 ja 6 5
## 371 3 3 4 4 4 4 4 5 4 ja 6 4
## 372 3 3 2 3 3 2 2 3 4 ja 4 1
## 373 3 3 2 3 3 2 2 3 4 ja 4 1
## 374 2 2 1 6 5 4 4 6 5 ja 2 2
## 375 2 2 2 5 5 4 6 6 6 ja 6 4
## V9_3 V9_4 V10_1 V10_2 V10_3 V10_4 V10_5 V10_6 Geschlecht
## 370 5 3 5 5 3 4 5 4 männlich
## 371 5 5 2 2 2 2 2 2 männlich
## 372 1 3 5 2 2 2 2 4 männlich
## 373 1 3 5 2 2 2 2 4 männlich
## 374 1 2 2 5 1 2 3 2 männlich
## 375 2 5 4 3 4 4 5 5 weiblich
## Bildungsabschluss key value
## 370 Keinen akademischen Abschluss Gesundheit 4.5
## 371 Keinen akademischen Abschluss Gesundheit 3.2
## 372 <NA> Gesundheit 2.6
## 373 <NA> Gesundheit 2.6
## 374 Keinen akademischen Abschluss Gesundheit 2.2
## 375 Uni Gesundheit 4.2Der Gesamte Datensatz hat sich nun bezüglich der Zeilenanzahl verdreifacht und anstatt der Variablen Stress, Erschoepfung und Gesundheit gibt in den letzten zwei Spalten eine Variable Key und Value. Key enthält die drei Variablen und Value den Wert dazu. Jetzt muss der neue lange Datensatz nur noch gespeichert werden mit data<-data%>%…
11 Mögliche Darstellung von Tabellen
Mit APA-Tables können viele Ergebnis in perfekter Form als Word Tabelle im APA Style gespeichert werden.
An den Code ist nur anzupassen:
- Datendateiname
- Variablenauswahl mit data[]
12 Wie kann ich vermeiden zu häufig gleiche Wörter zu verwenden?
library(tidyverse) library(tidytext)
lines <- read-lines (“text.Rmd”)
paper<- tibble (line= line) %>% unnest-tokens(word,line) %>% anti-join(stop_words) %>%
paper %>% count(word,sort=TRUS) %>% filter (n>20)